Keiko Okafor11/18/2025
Junior Developer (Career Transition) · Nonprofitarticle
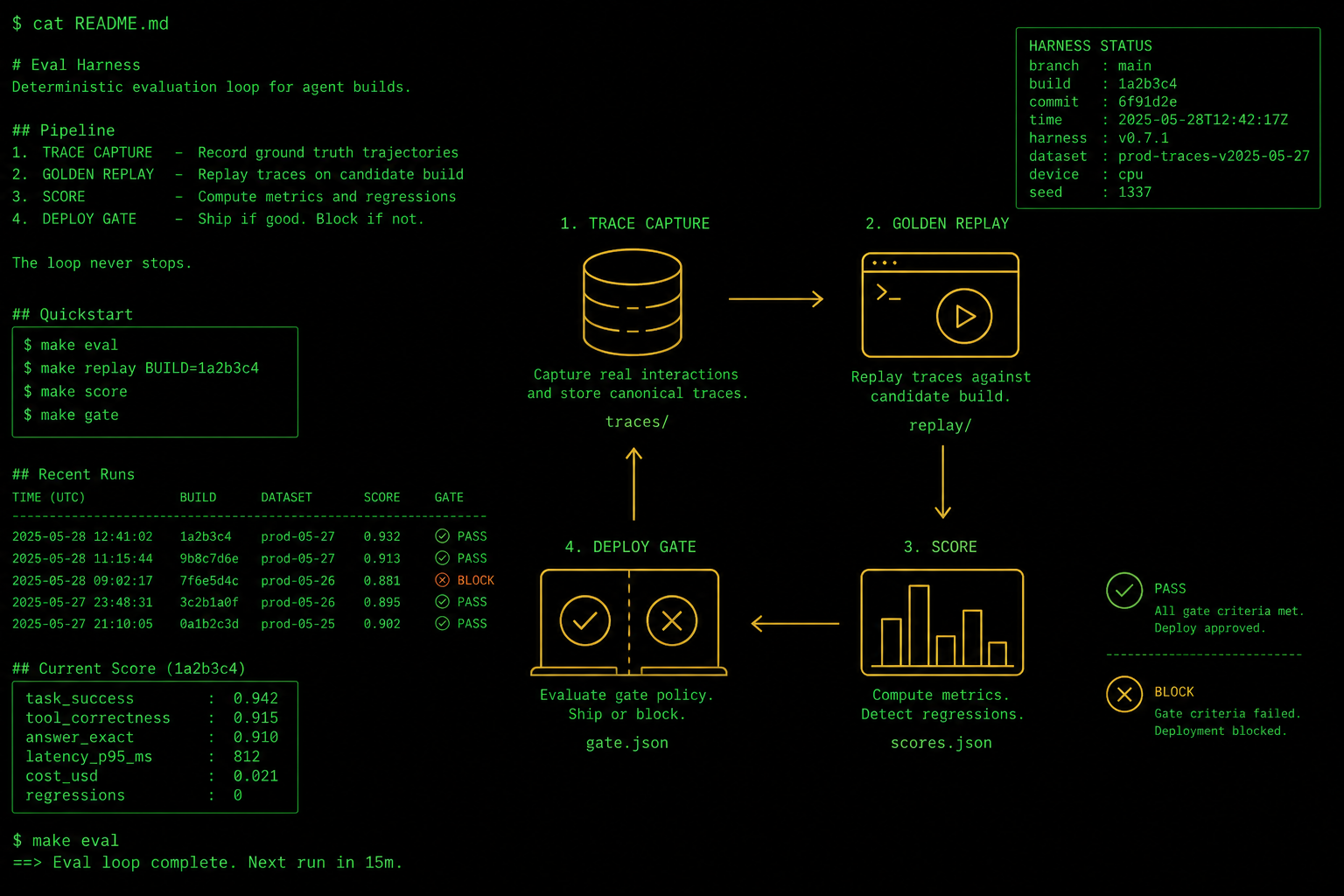
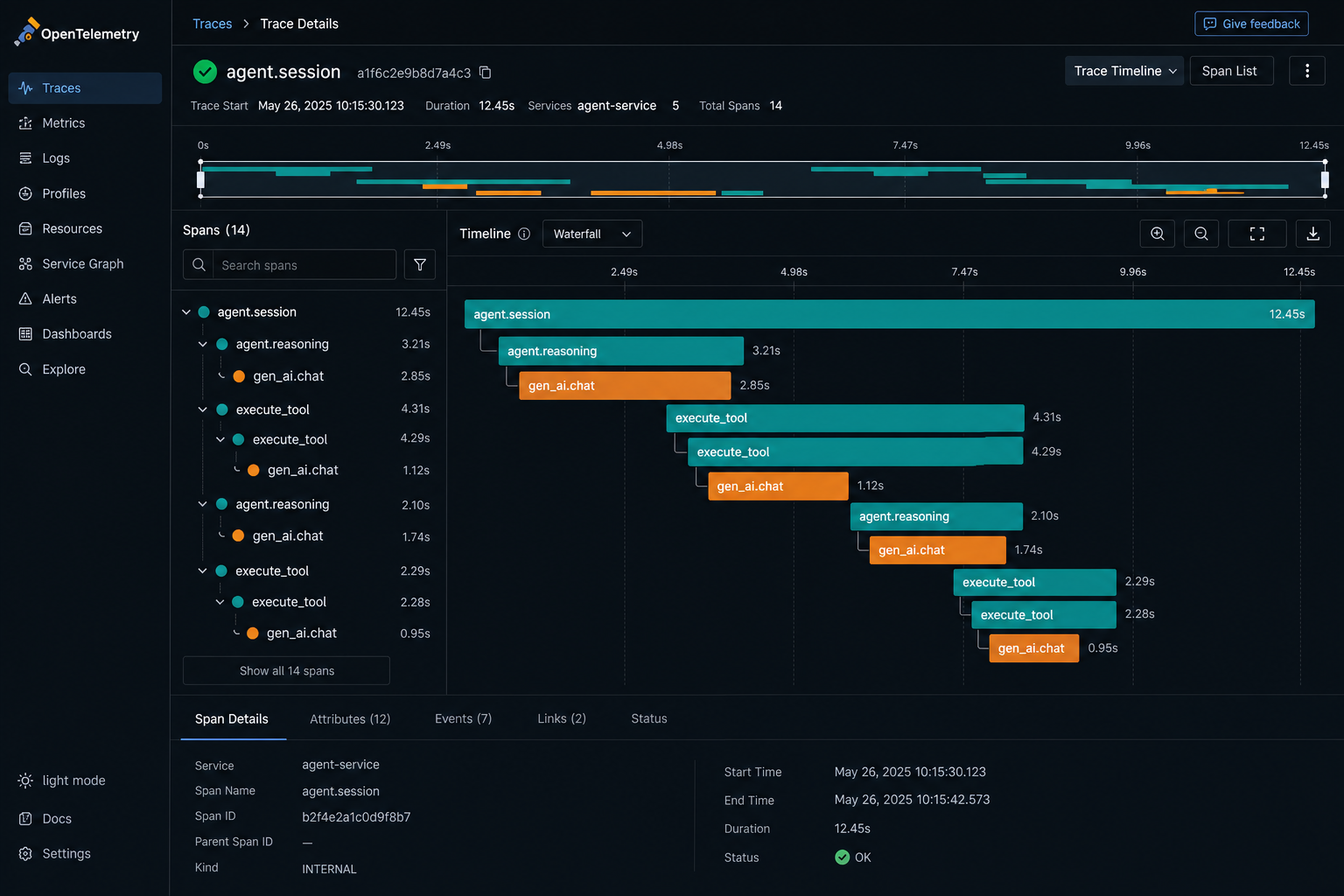
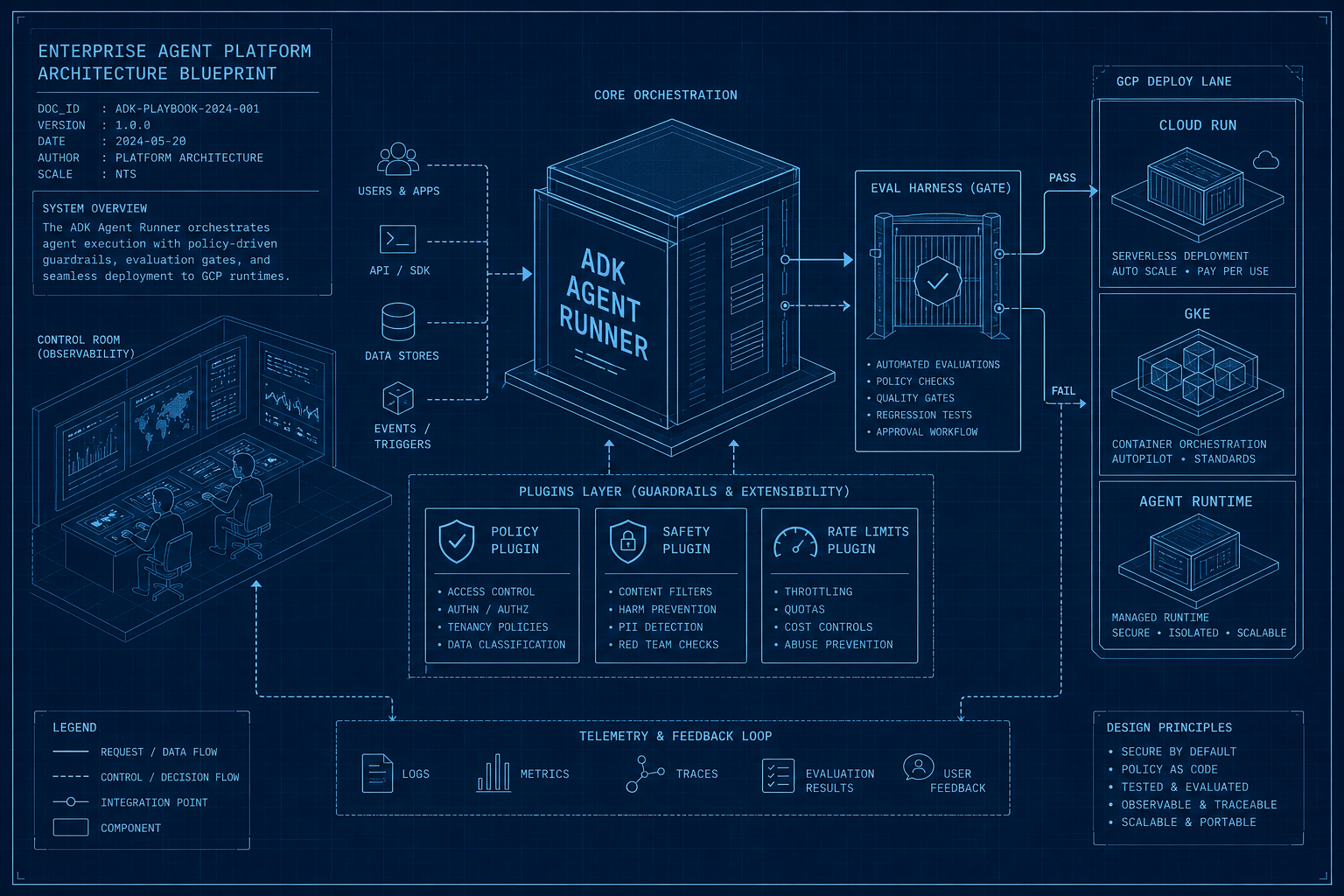
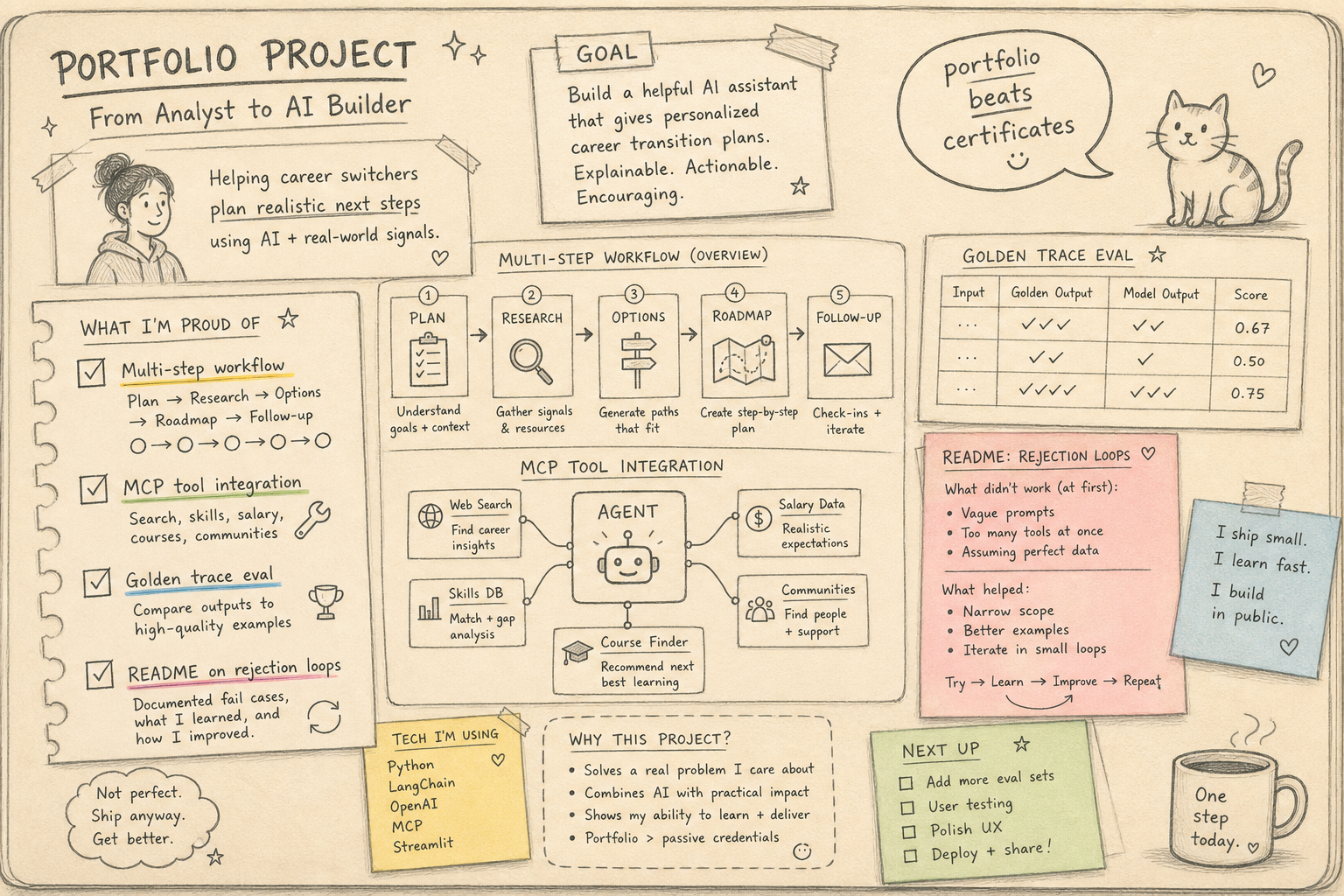
Portfolio beats certificates.
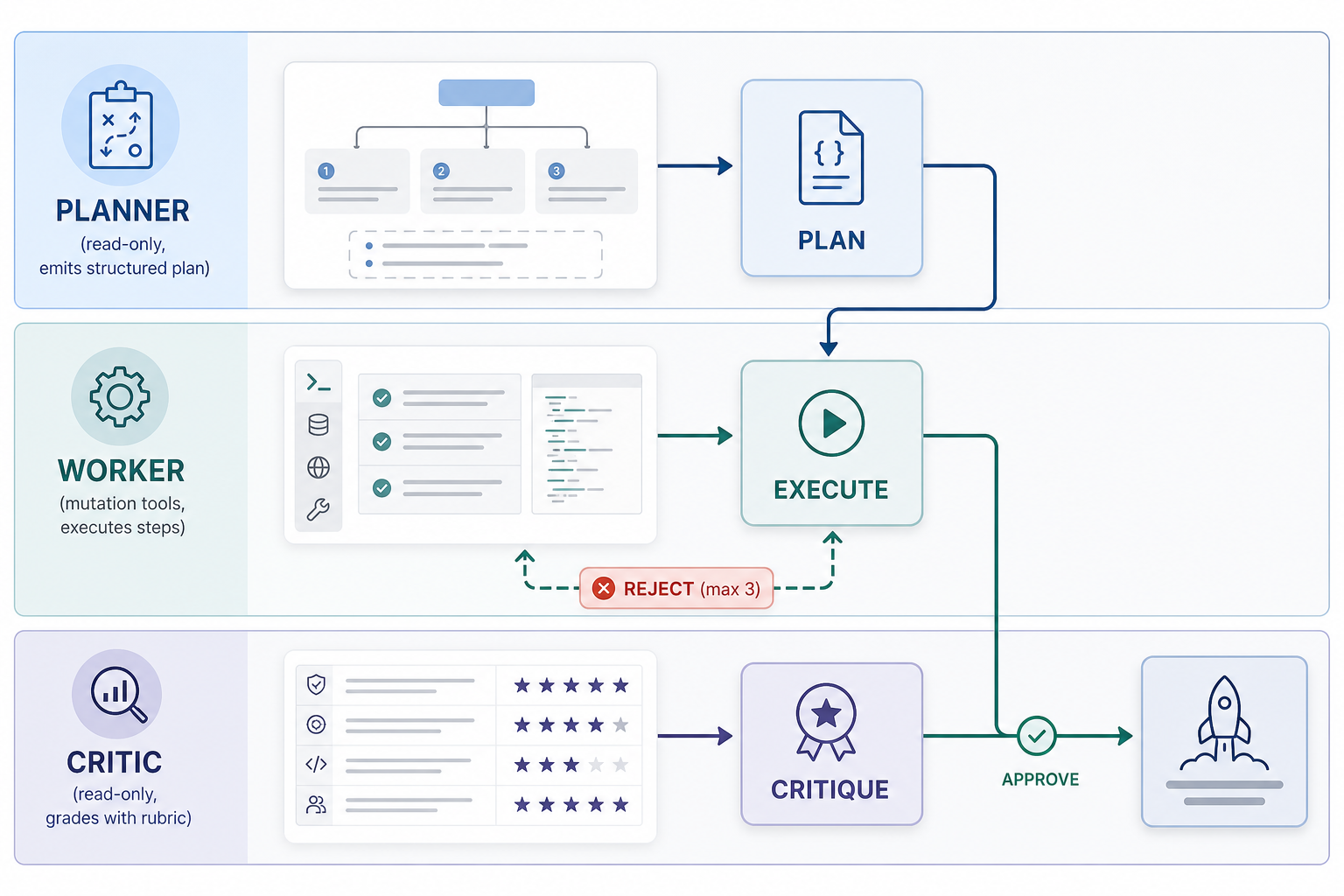
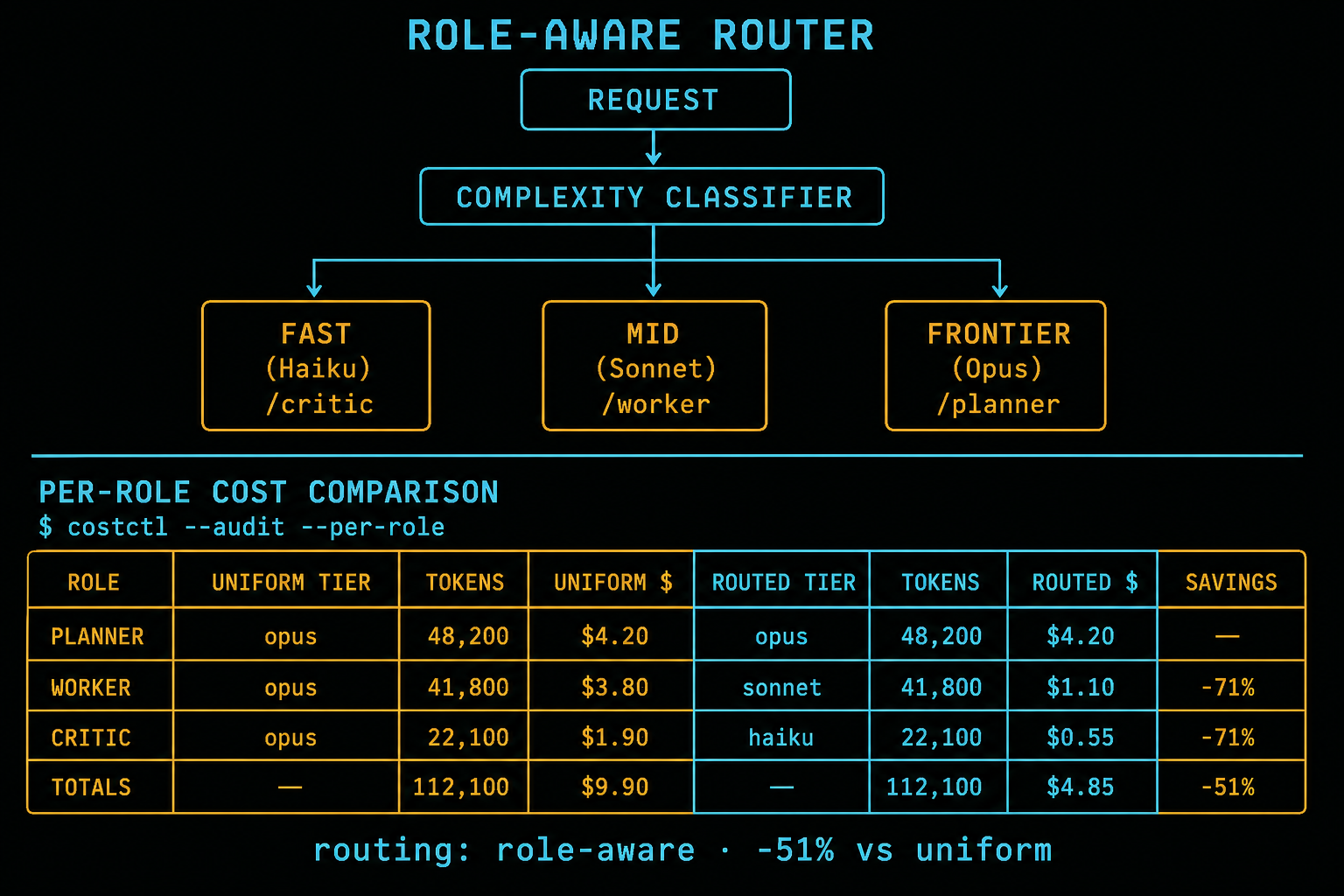
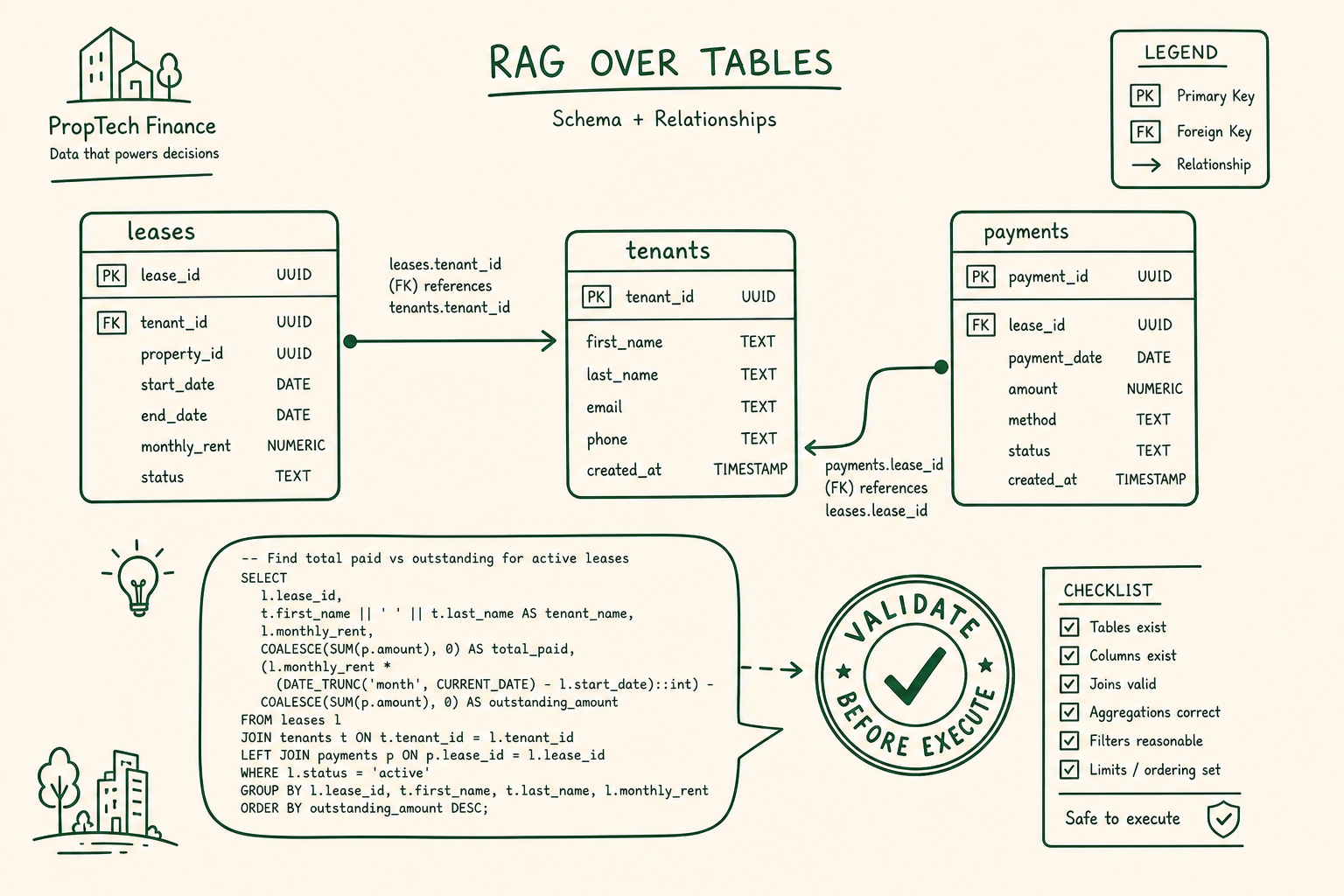
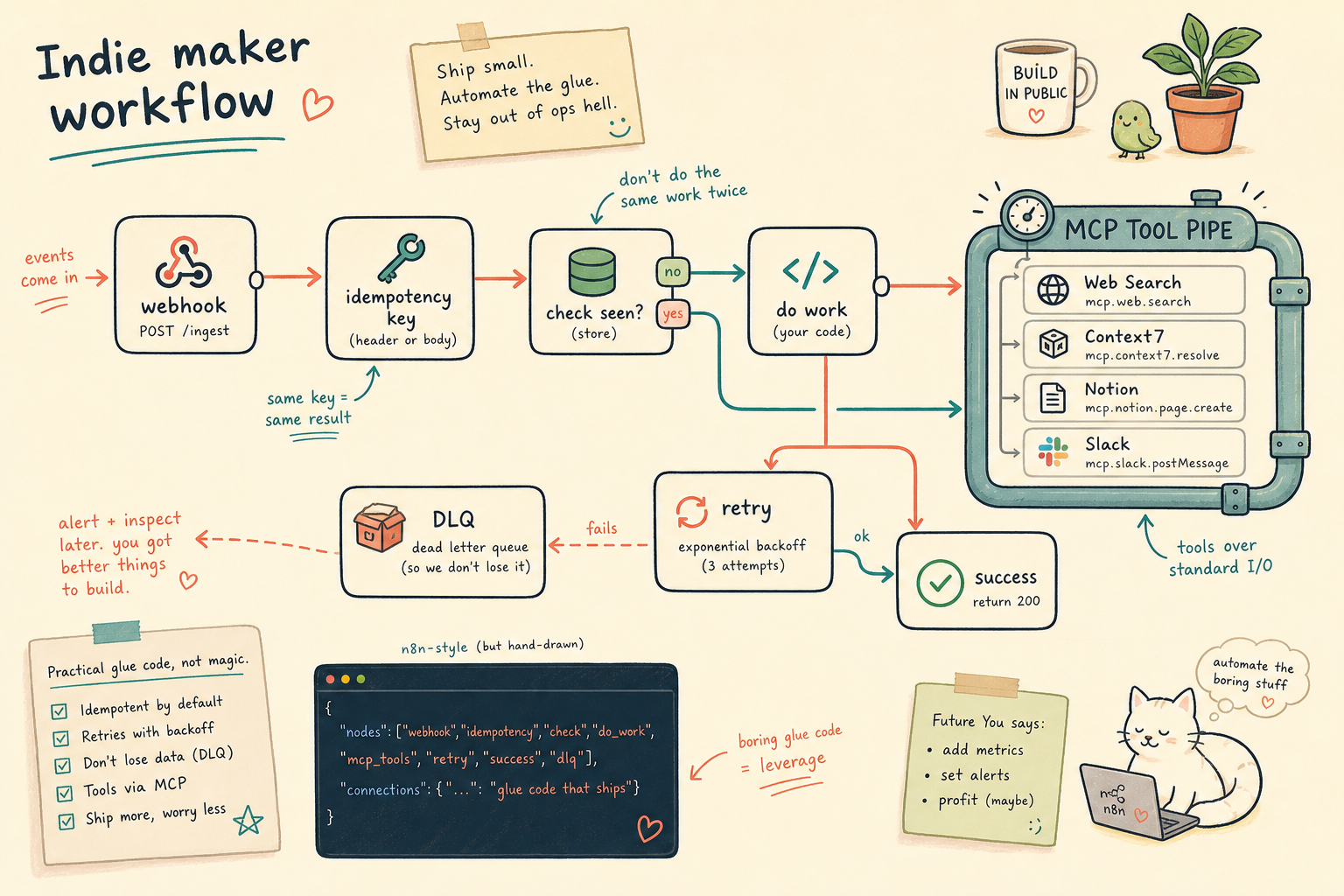
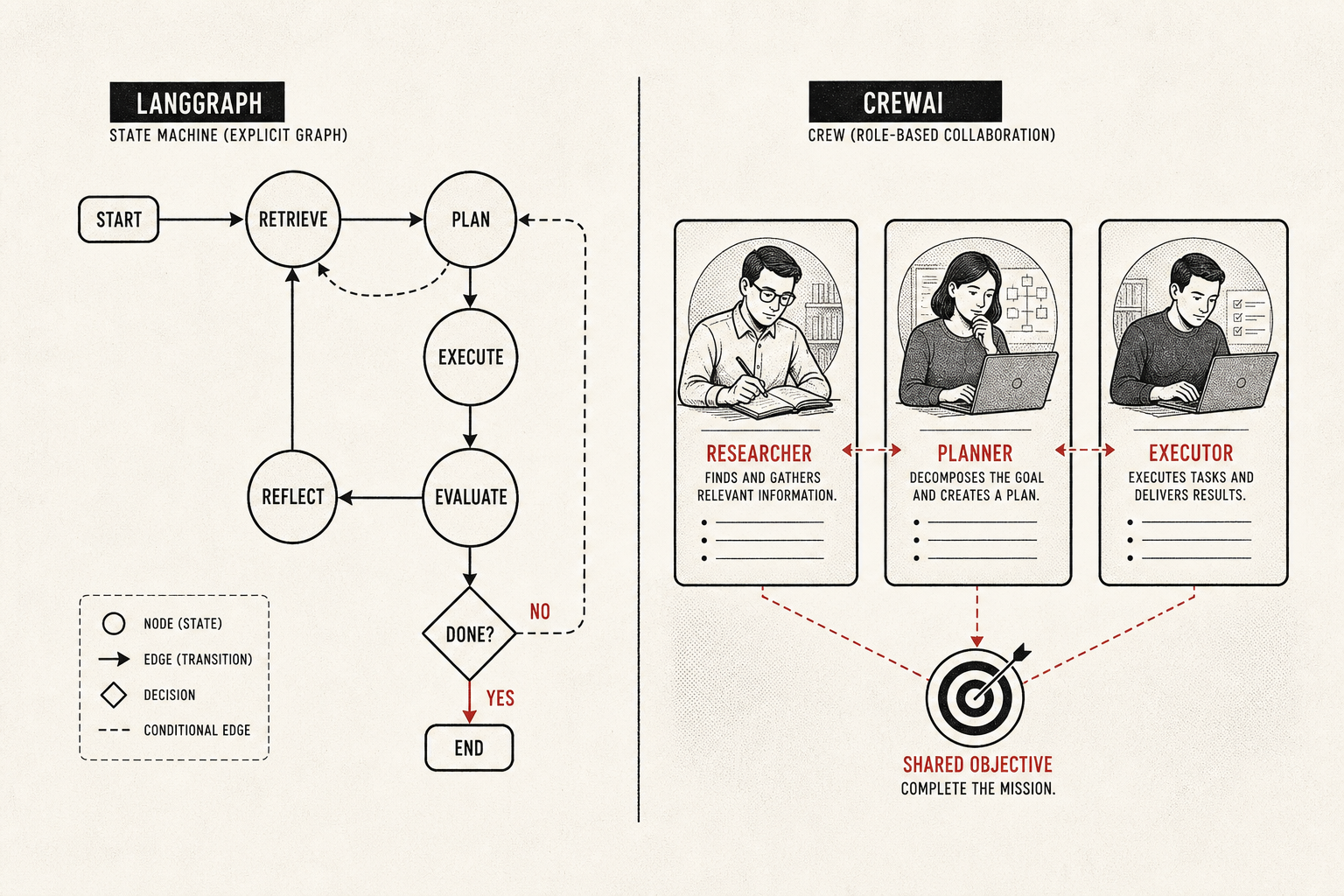
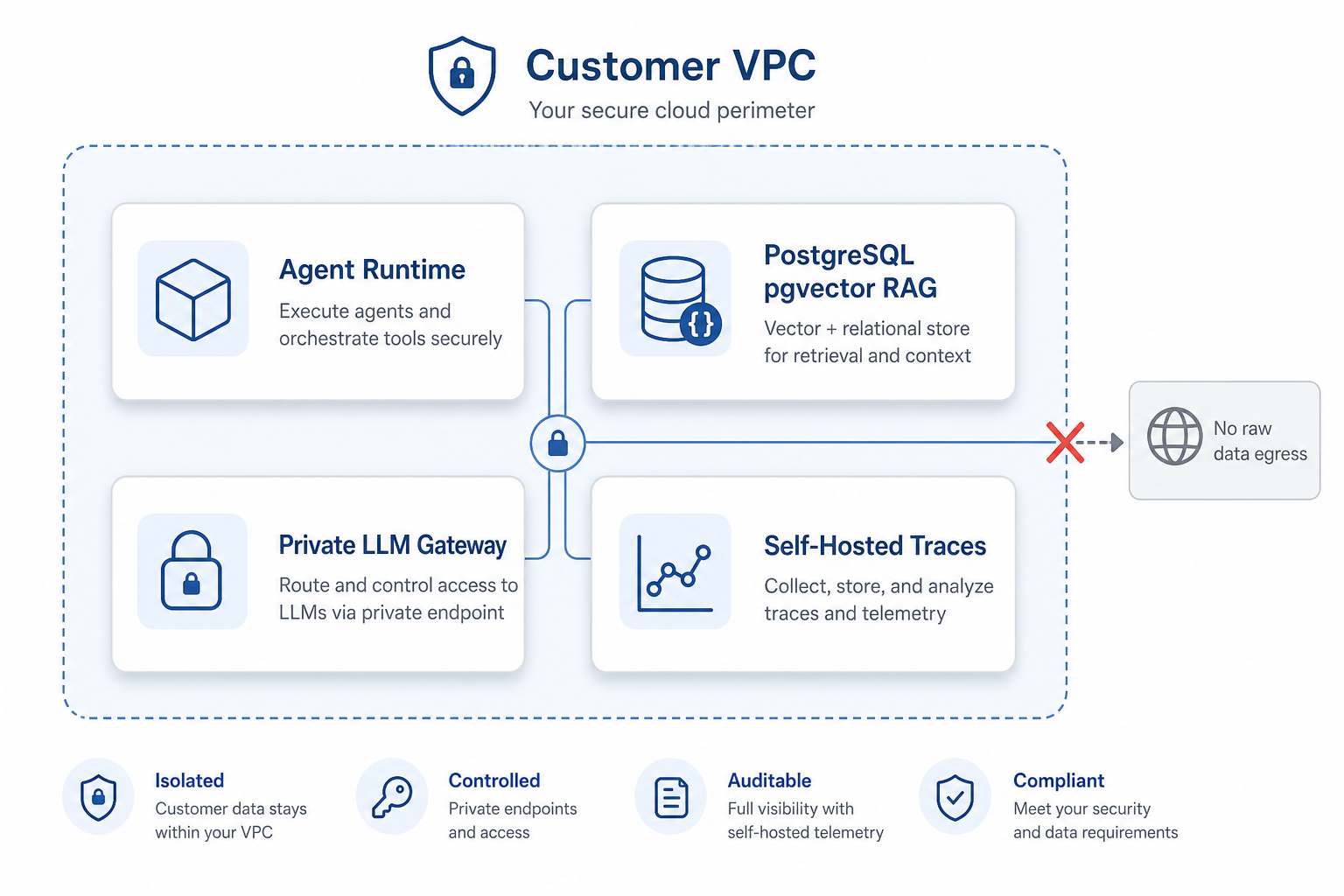
Hiring managers don't want another prompt course. They want evidence you can orchestrate rejection loops: eval harnesses, critic gates, and shipped agent workflows in public.