The wrong-quarter citation is the one that still wakes me up. We had a perfectly nice RAG assistant sitting on top of our PropTech finance warehouse, the kind of thing that answers "what was net operating income for the Riverside portfolio last quarter" without a human opening a spreadsheet. It worked in the demo. It worked for months. Then it told the asset team that Q3 revenue was a number that turned out to belong to Q2, and that number rode quietly into a board deck before anyone caught it. Nobody had touched the model. Nobody had touched the prompt. The bug was older and dumber than that: we had embedded our tables as if they were paragraphs, and vector similarity does not know the difference between a Q2 row and a Q3 row when both say "revenue" and both look like prose.
So let me state the thesis plainly, the way I wish someone had stated it to me before that deck went out. Tabular RAG needs schema-aware retrieval and symbolic execution, not vector-only chunking of CSV-shaped text. If your knowledge lives in a relational warehouse, the retrieval unit you care about is not a chunk of text. It is a table, a column, a join path, and a filter. Embeddings are still useful, but they belong on the schema and the descriptions, not on the data rows. This is the part the "RAG is solved" crowd skips, and it is the part that ships wrong numbers to executives.
The root causeWhy embedding rows betrays you
Here is the failure mode in one sentence, and it is worth sitting with: vector similarity on CSV-shaped text cannot preserve join logic or aggregations. When you dump rows into chunks and embed them, you are asking a cosine-similarity search to do a job that only a query engine can do. "Revenue for Q3" retrieves whatever rows are textually nearest to that phrase, and "nearest" is not "correct." The numbers that should have been summed, filtered, and grouped instead get matched, ranked, and pasted. The model then synthesizes fluent nonsense over the top, which is the worst kind of nonsense because it reads like an answer.
The research community has a tidier way of saying what I learned the hard way. As the Emergent Mind overview of RAG over tables puts it:
"Unlike pure text RAG, table-based RAG must contend with unique representational, retrieval, and reasoning complexities, including spatial table topology, schema heterogeneity, and multi-step or numerical inference."
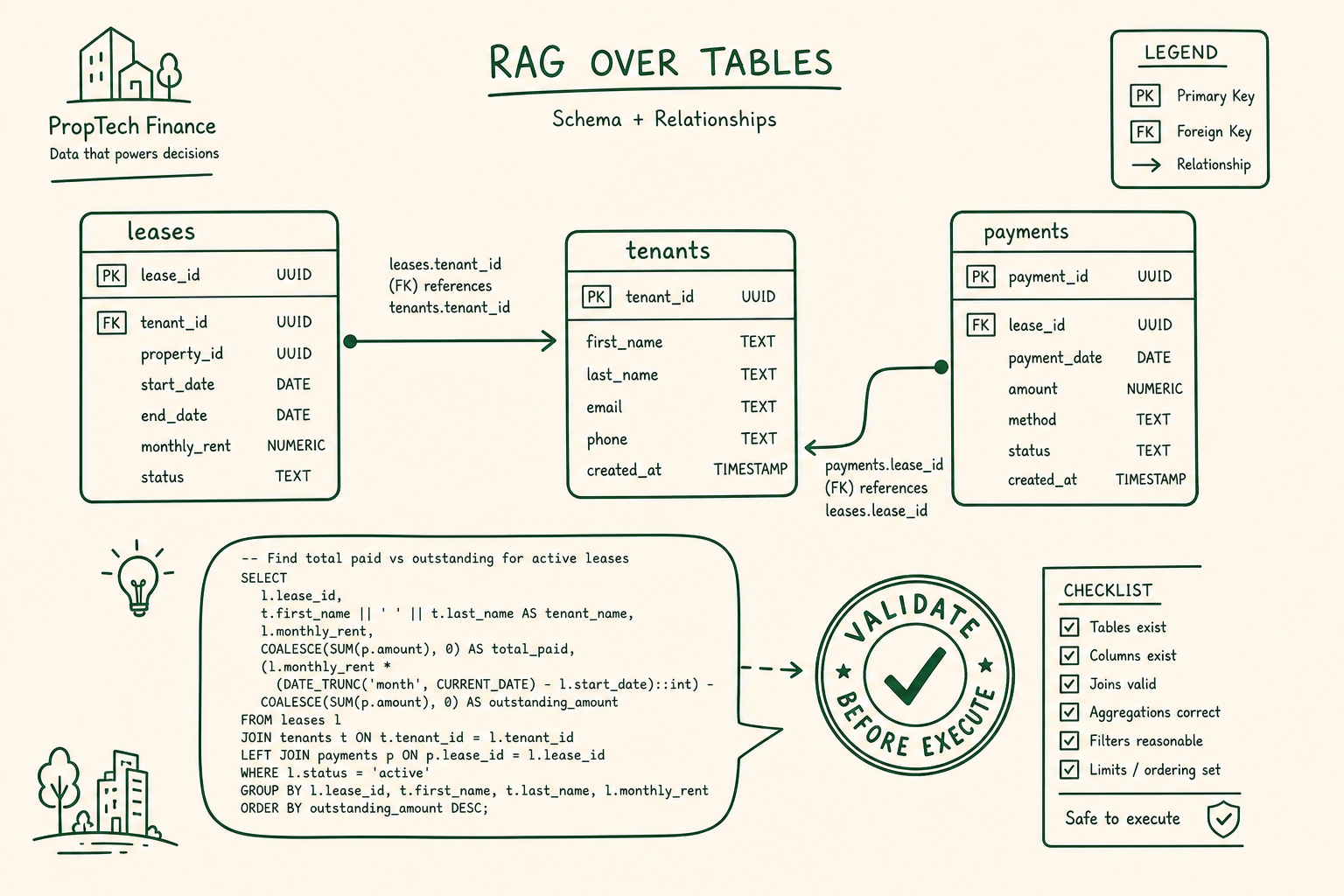
Read "spatial table topology" as "the position of a cell is its meaning." A value is the cell where its row and its column meet, and a quarter is a row key, not a vibe. Flatten that grid into a sentence and you delete the coordinate system that made the number mean anything. "Schema heterogeneity" is the second knife: a real warehouse is not one tidy table, it is leases joined to properties joined to payments joined to tenants, and the answer to a real question lives across that join, not inside any single chunk. No amount of overlap tuning fixes a problem that is fundamentally about structure. If your trauma is PDF tables rather than warehouse tables, that is a related but different fight, and I wrote up the parsing side of it in the enterprise RAG for PDFs notes. Today I am talking about data that is already relational and that we still managed to mangle.
The fix, in shape
Build three stores offline, reason over them online
The architecture that fixed this for us lines up almost exactly with what the TableRAG paper (arXiv 2506.10380) formalizes, and seeing it written down as a named pattern was a small relief, because it meant I was not just reinventing a workaround. TableRAG splits the world into two phases. Offline, you build the stores once. Online, you reason over them per query. The offline half is the part most people skip, and it is the part that earns the accuracy.
You build three stores from the same extracted tables. A text knowledge base of markdown descriptions and documentation, embedded for fuzzy lookup, because sometimes the question is "where do we even keep lease data" and that is a semantic search. A schema store that captures the structure itself: tables, columns, types, primary keys, and the foreign keys that define legal joins. And the relational database, untouched, because the actual rows should stay in the one system on earth that is good at filtering and summing them. The trick is that retrieval hits the first two stores, and only generated SQL touches the third.
Figure 1 · Offline build
One extraction, three stores, clean separation of jobs
Step oneExtract the schema before you extract anything else
If you do one thing this week, do this: stop thinking about your data and start thinking about your catalog. As AI21's structured-data guide lays out, structured RAG begins with INFORMATION_SCHEMA extraction, pulling tables, columns, primary keys, foreign keys, and types into something the retriever can reason over. Every warehouse already ships this. You are not building a catalog from scratch, you are reading the one your database has been maintaining all along.
This is the literal starting query I run on a new warehouse before I write a single line of retrieval code. It is unglamorous and it is the most important figure in this whole piece.
Figure 2 · Schema extraction
The first query you run, before any retrieval
-- Schema extraction starting point
-- index this, not your rows
SELECT table_name, column_name, data_type
FROM information_schema.columns
WHERE table_schema = 'finance'
ORDER BY table_name, ordinal_position;key_column_usage for primary and foreign keys, attach a one-line description and a few sample values per column, and you have the raw material for a schema graph. This catalog, not the rows, is what your retriever should be searching over.Once you have that result set, enrich it. For each table and column, attach a short natural-language description and a handful of sample values, then index those. Madhukar Kumar's extraction-strategy walkthrough makes the case I will repeat to anyone who will listen: descriptions plus sample rows plus relationships are what let retrieval pick the right table, and the foreign keys are what let SQL build a join that is actually legal. Skip the relationships and your model will happily invent a join that the database rejects, or worse, accepts and answers wrong.
The map
Your schema is a graph, so draw it like one
The moment the schema stopped being a flat list and started being a node-link graph in my head, the whole problem got easier to debug. Tables are nodes. Columns are the fields on each node. Foreign keys are the edges, and those edges are the only legal paths a join may travel. When the agent needs lease revenue by property by quarter, it is not searching for text, it is walking edges from payments to leases to properties and pulling the date column it needs to filter on. Retrieval's job is to hand the SQL generator the smallest connected subgraph that covers the question.
Figure 3 · Schema as a graph
Tables are nodes, foreign keys are the only legal join edges
payments.period, a typed date column. This is exactly the structure that disappears when you flatten rows into chunks. To guarantee the path is valid and minimal, SchemaRAG (ACM 2025) uses schema linking and Steiner-tree style pruning over this graph.This graph view is also why multi-table questions stop being scary. Pruning join paths with schema linking, the approach SchemaRAG formalizes with a SchemaLinker and a schema-augmented retriever, keeps the generator from wandering. You hand it a connected subgraph and a list of legal edges, and it composes joins that the warehouse will actually accept. If you have read my colleagues on agent design, this is the same instinct as giving a tool a tight contract instead of free rein, which the agentic architecture components piece covers from the systems angle. Constrain the surface and the model behaves.
The online loop
Decompose, retrieve schema, generate SQL, then validate before you run it
Now the per-query path, the half that runs every time a user asks something. TableRAG describes it as an iterative loop, and in practice it has five beats: decompose the question into sub-questions, retrieve the relevant schema subgraph, generate SQL, validate that SQL, and only then execute it against the warehouse and synthesize the result. The reason SQL sits at the center of this loop is not nostalgia for databases. It is that SQL is a formal language, and a formal language can be checked and executed exactly. The TableRAG authors put the principle better than I can:
"The utilization of SQL enables precise symbolic execution by treating table-related queries as indivisible reasoning units." (TableRAG, arXiv 2506.10380)
"Indivisible reasoning unit" is the phrase that fixed my mental model. A SUM over a filtered, grouped set is one atomic operation that either runs correctly or fails loudly. There is no halfway, no fuzzy-90%-similar revenue. That is the opposite of vector retrieval, where everything is a soft match and the softness is exactly where the wrong quarter slipped through. TableRAG backs this with HeteQA, a benchmark of 304 examples across nine domains, each requiring around five distinct tabular operations, which is a useful reminder that real questions are compound and need real execution, not a single lucky lookup.
But generated SQL is not free of sin, and here is where I have to be honest about the new failure mode you are buying. Text-to-SQL hallucinates too, just in a more catchable way. AI21 names the categories exactly:
"RAG systems using text-to-SQL may produce invalid queries, including syntax errors, incorrect table references, or missing filters, especially with complex schemas." (AI21, RAG for Structured Data)
Read "missing filters" and feel the cold spot in your stomach, because that is my wrong-quarter bug in its second life. A query that forgets the WHERE period BETWEEN ... clause does not crash. It returns a number, just the wrong one, aggregated across every quarter at once. Syntax errors are loud and self-correcting. Missing filters are silent and confident, which makes them the dangerous category. So we put a gate in front of execution.
Figure 4 · The validation gate
Three checks stand between generated SQL and your warehouse
The detail that makes the loop work, rather than just spin, is that the failure feedback is specific. "Invalid query" teaches the generator nothing. "Column revenue does not exist on payments; did you mean amount" or "no date filter present on a time-scoped question" gives it something to act on. We log every gate rejection too, because the rejections are a free dataset of where the schema descriptions are confusing the model, and tightening those descriptions retroactively prevents the next class of bad query.
The honest counterpointWhen this is overkill
I would be a hypocrite to sell you a pipeline as a cure-all right after telling a story about a pipeline that shipped a wrong number, so here is where text-to-SQL is the wrong tool. If your "warehouse" is one table with eighty rows that fits in a prompt, stand up nothing. Hand the table to a code interpreter and let it run pandas. Standing up schema extraction, a retriever, a generator, and a validation gate to query a spreadsheet is the kind of over-engineering that makes your on-call rotation hate you, and they would be right.
Two more caveats I owe you. First, TableRAG and SchemaRAG add real pipeline complexity, and a team without SQL literacy will struggle to debug a bad query, which means the validation gate's error messages are not a nice-to-have for them, they are the difference between a fixable system and a black box. Second, if your questions are governed enterprise metrics, "what is ARR by the official definition," a semantic layer like dbt metrics or Cube should front-run raw text-to-SQL. Let the agent ask the semantic layer for "ARR" and let the layer own the blessed SQL, so the definition of the metric lives in one governed place instead of being re-derived, possibly wrong, on every query. Raw text-to-SQL is for exploration. Semantic layers are for numbers that go in the board deck. I learned which is which the expensive way.
Wrap-upQuery the schema, do not search the rows
If you take one thing from my wrong-quarter trauma, let it be the reframing, because it is the cheap insight that the "bigger embedding model" pitch will never sell you. Tabular data is not a pile of text that happens to have commas in it. It is a structured system with a coordinate grid, typed columns, and legal join paths, and the right retrieval target is the schema, not the rows. Build the three stores offline. Extract the schema first. Draw it as a graph. Generate SQL, then gate it on syntax, references, and filters before it ever touches the warehouse. The numbers stop being approximate, and approximate is the only thing that was ever wrong with them.
Do this this week
Take your worst tabular RAG question, the one that quietly returns a plausible wrong answer, and trace it. If the retrieval step is pulling row chunks, you found your bug. Run the INFORMATION_SCHEMA query from Figure 2, index the catalog instead of the rows, and put a single check in front of execution: does a time-scoped question carry a date filter? That one check is the gate between your assistant and a wrong-quarter board deck.
None of this requires a frontier-model upgrade or a new vector database. It requires treating the warehouse like a warehouse and the schema like the map it already is. Build the gate first, draw the graph second, and let the embeddings go back to the one job they were ever good at, which is finding the right table, not computing the right number.
Tables are not prose. Retrieve the schema, execute the SQL, validate the filters. The wrong quarter never makes the deck again.
Comments (3)
Join the discussion
Sign in to comment, bookmark threads, and continue lessons across sessions.