A grower-facing support agent we shipped last season had a tell. Every morning, the first user who signed in got the same opening line: a polite reintroduction, a request for the field ID it had been handed the day before, a re-ask of the crop and the region it had already been told. The model had not regressed over the weekend. The team had simply decided that "memory" meant the chat transcript, and the transcript reset with the session. So the agent walked into the same room each morning and introduced itself to people it had worked with a hundred times.
The vendors describe the symptom well. Moxo puts it plainly in its architecture overview: without persistent memory, an agent is "perpetually introducing itself at a party it's attended a hundred times." That line got passed around our team for weeks, because it named exactly what we had built by accident. The deeper point is that the fix is not to stuff the transcript somewhere persistent. The transcript is the wrong shape. What production needs is structured state, and structured state has tiers.
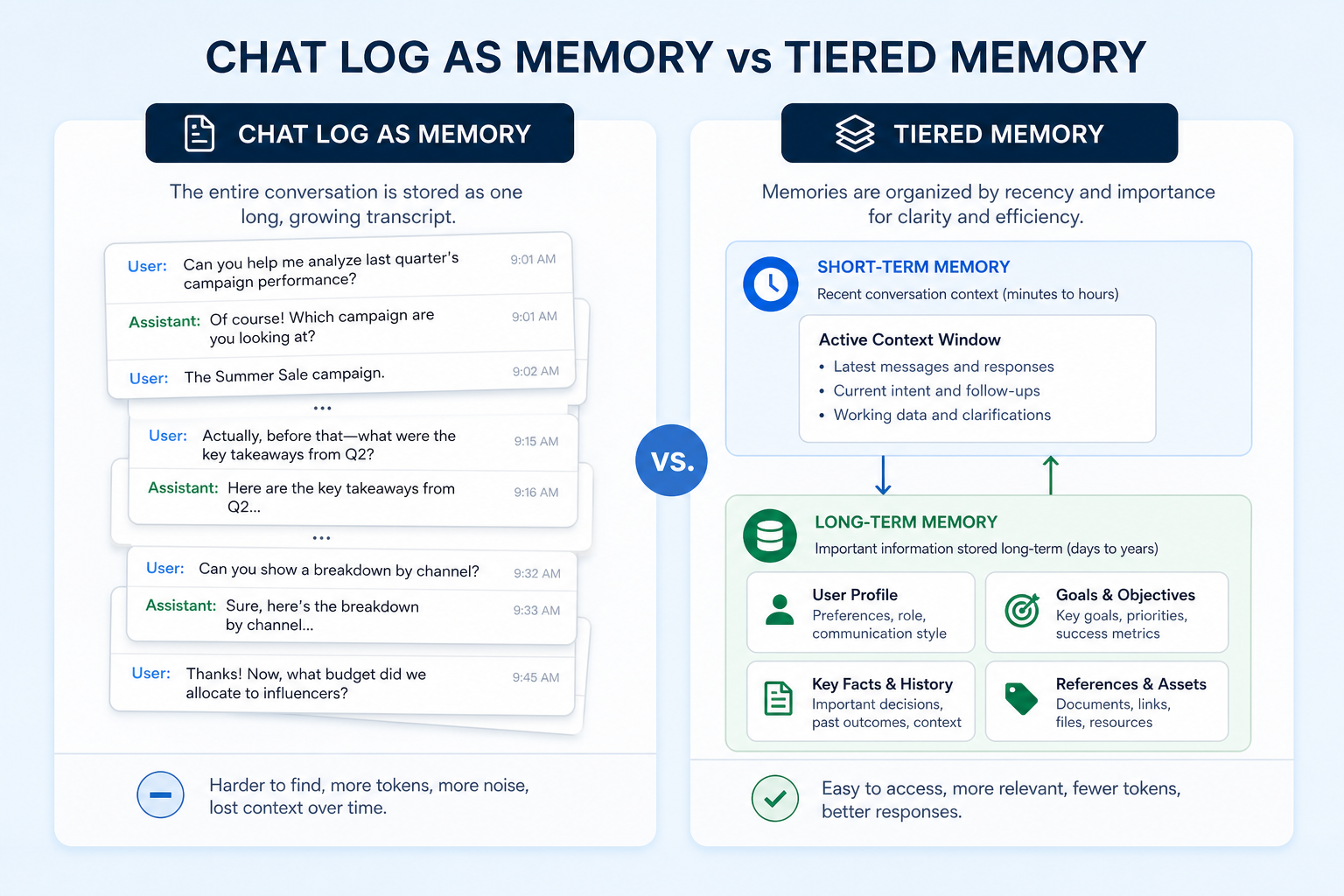
The transcript is not memory
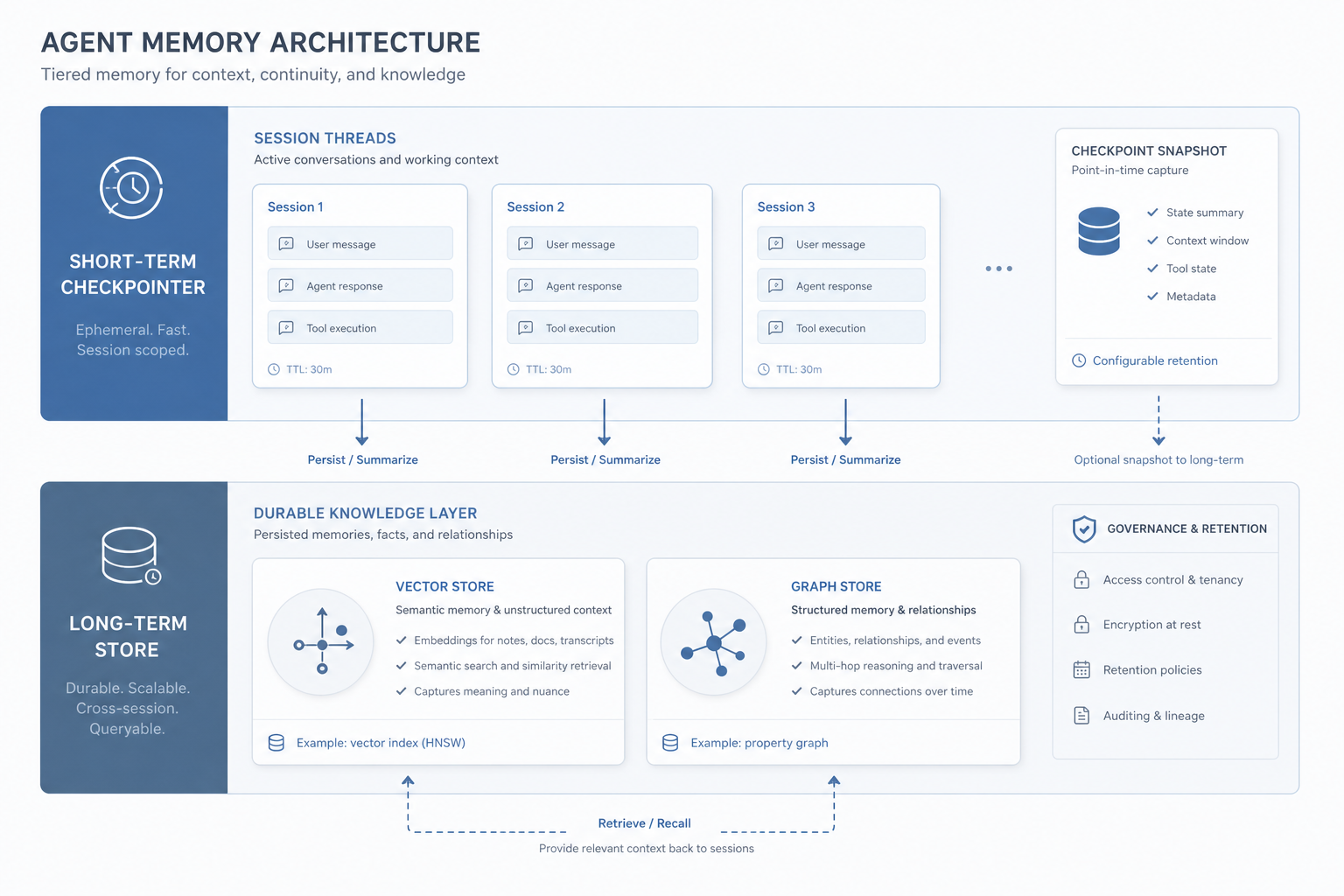
When people say "the agent has memory," they almost always mean one thing, when the system actually needs two. Clarion AI, writing on production multi-agent systems, draws the line cleanly: production agents need at minimum a short-term checkpointer that persists conversation state within a session, and a long-term store that retrieves user-specific or domain knowledge across sessions. Two tiers, two contracts, two failure modes. Conflate them and you get the morning reintroduction at best, and a cross-tenant data leak at worst.
Figure 1 · The decomposition
Two swimlanes: working memory and durable memory do different work
Problem: a single "memory" bucket forces one set of rules onto two workloads that want opposite things. Constraint: working state has to be fast and cheap to write on every tool loop, while durable state has to be auditable and never silently overwritten. Recommendation: separate the stores physically, not just logically. A session checkpointer for the working tier, a deliberately distinct vector or graph store for the durable tier, and no code path that writes to both with the same call.
Split two
Episodic logs versus semantic facts
Even inside the durable tier, there is a second split that teams miss. Episodic memory is what happened: the raw turns, the timeline, the noisy back-and-forth. Semantic memory is what is true: the field is forty hectares, the account is on the regulated tier, the user prefers metric units. The expensive mistake is treating these as the same thing and pouring whole transcripts into a vector database, then calling retrieval "long-term memory." Retrieval then hands the model yesterday's small talk instead of the one fact that mattered.
The retrieval machinery for the durable tier is where the vendor patterns converge. Exabeam, in its architecture explainer, notes that long-term memory typically combines vector stores for semantic recall with knowledge graphs for relationships and provenance. That pairing matters in a compliance setting: the vector store tells you a fact is relevant, and the graph tells you where it came from and what it is connected to. If memory is one of the system components you are still mapping, it's worth taking a look at the broader decomposition of an agentic system, where memory sits as one component among six.
Who is allowed to read this row?
This is the question I ask first on any memory design, and on a multi-tenant platform it is not optional. The moment your durable store holds facts from more than one customer, every write and every read is a potential cross-account leak. A vector index does not know that embedding number 9,481 belongs to a different grower than the query that just came in. You have to enforce that, and you have to enforce it on the store, not in the prompt.
Problem: semantic search is similarity-based, so without a hard filter it will happily return the closest match from any tenant. Constraint: in regulated industries, "the model usually does not surface other accounts" is not a control an auditor will accept. Recommendation: row-level isolation on every memory store, with the tenant identifier as a mandatory partition key on both write and query, enforced below the application so a forgotten filter fails closed rather than open. Treat a long-term write without a tenant key as a build break, not a code-review nit.
Working memoryThe checkpointer is scoped to a thread
Concretely, the working tier is a checkpointer keyed by a thread or conversation identifier. LangGraph's persistence model is a clean reference here, and the one I point teams to: a checkpointer persists the state of a single run under a thread_id, while a separate store handles cross-thread retrieval for user and organization context. The two keys are different on purpose. Working state is keyed by the conversation. Durable state is keyed by who the conversation is for.
Figure 2 · Scope keys
Checkpointer keyed by thread, store keyed by tenant and user
So the durable tier should never receive a raw transcript. It receives facts that have been pulled out of the transcript on purpose, with a source attached. That extraction step is the part teams skip, and it is the part that makes the difference between memory you can audit and a vector index full of yesterday's chatter.
From transcript to durable fact
Figure 3 · The extraction pipeline
Transcripts become facts only after extraction, validation, and provenance
Problem: raw transcripts are episodic and noisy, so persisting them directly gives you recall without precision and storage without provenance. Constraint: a fact you cannot trace to a source is a fact you cannot defend, correct, or delete on request. Recommendation: run an explicit extraction step that turns turns into typed facts, dedupes against what is already stored, scopes each fact to its tenant, and stamps it with provenance before it lands in the durable store. The transcript can be retained separately for replay; it just does not get to be the memory.
But the context window keeps growing
The fair counterpoint, and I hear it in every design review, is that context windows are getting large enough to hold the whole history, so why bother with external memory at all. Just paste it all in. It is a real argument, and for a prototype it is often the right call. At enterprise scale it falls apart on three axes the window size does not fix.
Cost and latency scale with every token you re-send, so replaying a long history on each turn is a bill that grows with tenure rather than value. Auditability does not come for free with a bigger window: a fact buried in a 200,000-token prompt is not governed, scoped, or deletable. And memory injection widens the attack surface, because anything you feed back into the prompt is a place for prompt injection to hide, which is why retrieved memory has to be sanitized and access-controlled before it reaches the model. A bigger window changes what you can do; it does not change what you can defend. What you choose to load, and at what altitude, is itself a design decision. An interesting read for that is the piece on context engineering altitudes, which applies directly to deciding what earns a place in memory.
MondayAudit the memory you already shipped
You do not need a rewrite to start. Take the agent already in production and run it through six questions. Each one maps to a contract from the tiers above, and the first one you answer with a shrug is your next incident.
Figure 4 · The Monday audit
Six questions, each with a status you can defend
Do this Monday
Open your agent's memory writes and find the single line that persists to the long-term store. Then ask: is the tenant key on that line, and is it impossible to call this path without it? If the answer is "usually" or "we add it in the service," you have a leak waiting for traffic. Make the key mandatory at the store boundary, not a habit at the call site.
What memory is, once you stop calling it the transcript
None of this is exotic. It is the same discipline we bring to any system of record: separate the hot path from the durable path, scope every row to its owner, keep provenance, and write down a deletion policy before someone asks for one. Agents make it feel new because the reasoning core is probabilistic and the inputs are conversational, but the store underneath is sober data engineering, and that is exactly why it holds up under a regulated load.
So the agent that stops introducing itself every morning is not the one with the largest context window. It is the one whose working state is scoped to the run, whose durable facts are scoped to the customer, and whose memory was designed as structured state instead of inherited from the transcript. Draw the two swimlanes for your own system this week, then go find the write that is missing its tenant key.
Episodic logs tell you what was said. Structured state tells you what is true, who it belongs to, and where it came from. Only one of those is memory you can ship.
Comments (4)
Join the discussion
Sign in to comment, bookmark threads, and continue lessons across sessions.