I copied a stdio MCP tutorial into staging on a Thursday. It worked on the first try, which should have scared me more than it did. The server spoke the protocol, the agent called the tools, the demo was clean. What I had actually shipped was a bearer token that was god-mode: any client that held it could call any tool, against any tenant's data, with no log that tied a call back to a human. By Friday afternoon a support agent had used the "read invoice" tool to read a different customer's invoices, and I was on the phone explaining why we had no audit trail. The model did nothing wrong. The seams did.
So this is the piece I needed that Thursday. Not a "hello world" server, but the production checklist: what breaks first, the four topologies worth knowing, an auth stack that survives an audit, and the gateway that keeps a growing estate from becoming a liability. I have wired more than fifteen webhook integrations and I am now doing the same job for MCP servers, and the lesson rhymes every time. The protocol is the easy part. The contracts and the governance are the work.
What breaks first, and it is never the model
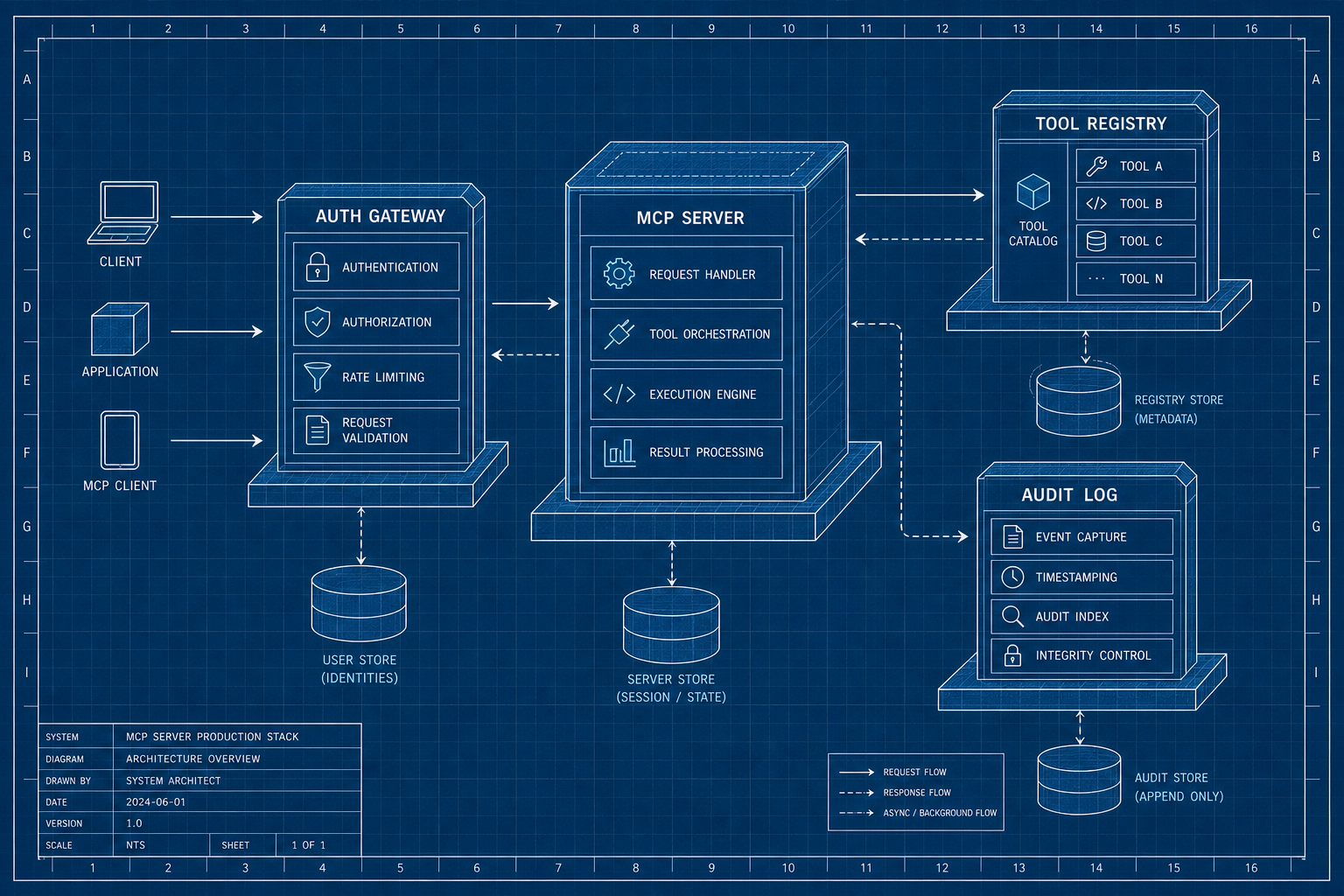
When an MCP deployment falls over in production, the post-mortem almost never lands on the model. It lands on three seams, in roughly this order. One: token passthrough, where the server reuses whatever credential the client handed it instead of getting its own scoped token, so a leaked or over-broad token becomes total access. Two: missing schema versioning, where a tool definition changes shape under a running agent and every caller silently starts sending malformed arguments. Three: a missing audit triple, where you cannot answer "which user, through which agent, called which tool" after the fact. Notice that none of these are MCP-specific genius. They are the same integration hygiene we have owed every API for twenty years. MCP just makes it trivially easy to skip them, because the quickstart does.
The audit triple deserves a beat of its own, because it is the one that turns a bad day into a bad week. In a classic API you usually have a user identity and a route, two of the three. With agents you gain a middle layer: the agent acted on the user's behalf, and the tool ran on the agent's behalf. If your log only records "the server got a call," you can reconstruct neither intent nor accountability when someone in compliance asks. Log all three, on every call, or accept that your incident reviews will end in a shrug.
Step 1Pick a topology before you pick a transport
The first real decision is not stdio versus HTTP. It is what shape your estate takes, because that determines everything downstream about isolation and auth. Digital Applied's enterprise patterns writeup sorts production deployments into four topologies, and naming yours up front saves you a migration later.
Figure 1 · Deployment topologies
Four shapes an MCP estate actually takes
My rule of thumb: most SaaS-shaped products land on row-isolated multi-tenant, and the moment you have more than two or three servers you graduate to a federated gateway. Edge-cached read-only is the underused one. If a tool only reads, caching it at the edge gives you speed and shrinks the blast radius to nothing, because there is nothing to corrupt.
The cost of guessing wrong here is a migration, not a config flag. Row isolation that you bolt on after launch means re-keying every write you already shipped, and a gateway you add late means rewriting auth in every server at once. Spend the thirty minutes to name the topology before the first commit. It is the cheapest decision in this whole piece and the most expensive one to defer.
Step 2 · Authorization
Auth that survives an audit
Here is the part the tutorials skip entirely. The MCP spec revision dated 2025-11-25 does not treat auth as optional for remote servers: it mandates OAuth 2.1 with PKCE using S256 for remote HTTP servers, per Digital Applied's reading of the spec. That is the floor, not the ceiling. A production auth stack has three more pieces stacked on it.
First, publish Protected Resource Metadata (RFC 9728) so clients can discover where to get a token and what scopes exist. Second, use Resource Indicators (RFC 8707) on token requests so a token minted for your server cannot be replayed against a different one. Third, and this is the one teams fight me on, support the Enterprise-Managed Authorization extension so an IdP like Okta or Azure AD sits between client and server and an admin can revoke access from the same console they use for everything else.
Figure 2 · The token path
Client to gateway to server, with a scoped token at each hop
It helps to see auth, observability, and governance as named modules rather than a vague "we'll secure it later." This is the platform view I sketch for stakeholders who think MCP is just a library import.
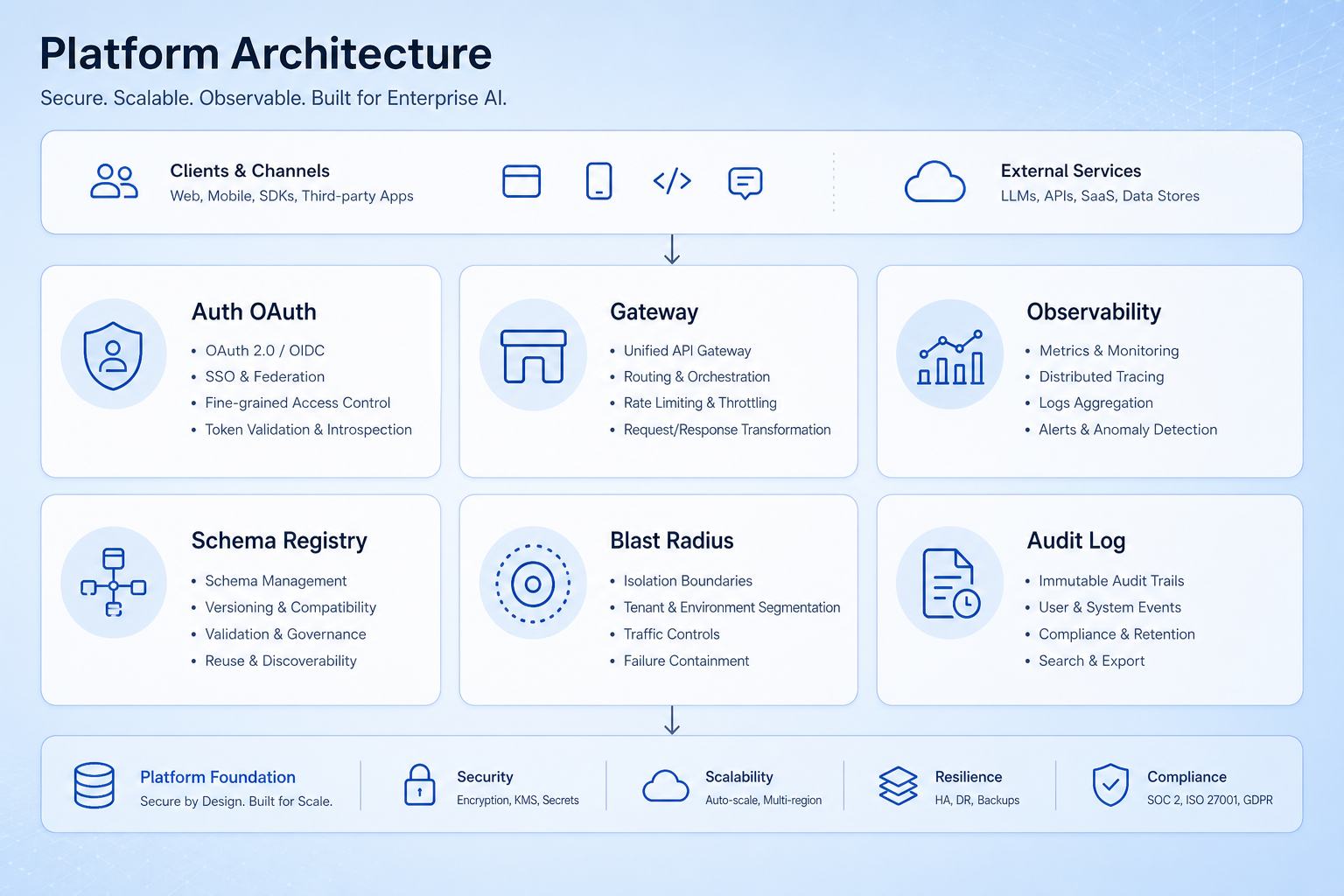
Source: adapted from Digital Applied, MCP Server Patterns for Enterprise AI Agents (2026).
Why is token passthrough a fireable mistake?
I want to be blunt about the single most common gap, because it is the one that paged me. Token passthrough is when your MCP server takes the credential the client presented and reuses it to call upstream systems. It feels efficient. It is forbidden. Digital Applied states it flatly:
"Token passthrough is explicitly forbidden." (Digital Applied, MCP Server Patterns 2026)
The reason is blast radius. A passed-through token carries the client's full authority, so the instant the server is compromised or simply buggy, the attacker inherits everything that token could do, which in my Friday incident was every tenant's invoices. The fix is mechanical: the server obtains its own scoped credentials and exchanges or upstreams with those. The security writeup at Systems Hardening frames why this gap is so widespread:
"Most production deployments treat auth as 'the bearer token grants everything.' The specific gaps..." (Systems Hardening, MCP Authentication Patterns)
If you take one thing from this section: a bearer token should authorize a specific tool at a specific scope, never the whole server. Per-tool authorization is the cheap insurance the quickstart never sells you.
Once you have more than a couple of servers, the auth and audit logic stops wanting to live in each one. It wants a single front door.
The gateway earns its keep at scale
A gateway is just the federated topology from Figure 1 with teeth. It centralizes the three things you do not want to reimplement per server: audit, rate limits, and policy. WorkOS calls the gateway pattern a 2026 roadmap item for exactly this reason: as estates grow, per-server governance does not scale, and admins want one console. As they put it:
"IT administrators should be able to manage MCP server access from the same identity provider console where they manage everything else." (WorkOS, Everything your team needs to know about MCP in 2026)
The mental model that made this click for me: the gateway sees every call, so it is the only place where "who called what" is a complete record rather than a fragment scattered across servers. Cross-app token exchange patterns like WorkOS Cross App Access ride on the same idea: one mediated boundary, not N ad hoc ones.
A fair counterpoint before you over-build: the fully enterprise-managed auth extensions are still maturing, pre-RFC by WorkOS's own account, so do not wait for a finished standard to ship something safe. The pragmatic move today is an AuthKit or IdP bridge in front of the gateway now, with a clean seam so you can swap in the standardized extension when it lands. Boring, incremental, and it keeps you out of the Friday pager rotation while the spec settles.
Figure 3 · The choke point you want
Every call passes the gateway, so every call is logged
Blast radius
Version your tool definitions like an API
The last seam is the quiet one, and it is the one I see skipped even by teams that nailed auth. Tool definitions are an API contract, and they change. When you rename an argument or tighten a type without versioning, every running agent that cached the old schema starts sending calls that are subtly wrong, and because the model will gamely keep trying, you get garbage rather than a clean failure. Treat tool definitions like any other public API: version them, and let callers pin a version.
Pair versioning with per-tool blast-radius limits. A "send email" tool should have a rate ceiling and a scope that cannot touch the billing system, independent of whatever the caller's token theoretically allows. The principle is the same one from retries and backoff: assume the call will misbehave, and bound what it can do when it does. A tool that can fire a thousand times a second because nobody set a ceiling is not a tool, it is an outage waiting for a trigger.
One more habit from years of webhook work: make the failure mode boring. Return a typed error with a version stamp, not a stack trace or a half-written payload, so the calling agent can back off and retry instead of looping on garbage. Versioned schemas and bounded tools are what let a flaky dependency degrade quietly rather than cascade. Here is the production checklist I keep taped to the laptop, drawn as a ladder because each rung depends on the one below it.
Figure 4 · Ship checklist
Five rungs between a tutorial and production
Do this Monday
Open your live MCP server and check exactly two things. First, does any tool authorize on the bearer token alone, with no per-tool scope? If yes, that is your token-passthrough hole, fix it before anything else. Second, can you produce the user, agent, and tool for a call that happened last week? If you cannot, you have no audit triple, and the next incident will be unexplainable. Both are an afternoon of work and they are the two that page you.
None of this is exotic, and that is the point. It is the boring glue: scoped tokens, a gateway that logs, versioned contracts, bounded tools. The stdio quickstart is genuinely great for local development, so keep using it there. Just do not let it walk into production wearing a tie. For where MCP servers sit inside an agent's package manifest alongside skills and hooks, the breakdown of hooks and skills is worth a look. And if you are still placing MCP in the bigger picture, it's worth taking a look at how the components of an agentic system fit together, where this is the tools and integration layer.
The protocol takes an afternoon. The contracts and the governance take the rest of the quarter, and they are the actual job.
Wire one server properly this week, climb all five rungs, and the second one is a template. That is the whole trick to an estate that survives traffic: do the unglamorous half first, so the demo that dazzles on Thursday does not page you on Friday.
Comments (4)
Join the discussion
Sign in to comment, bookmark threads, and continue lessons across sessions.