Friday afternoon, an agent in our document-review pipeline kept summarizing the wrong clause in a contract. Someone tightened the system prompt, eyeballed three runs, declared victory, and shipped. Monday morning the same failure walked back in wearing a slightly different contract, and we found out from a paralegal, not a dashboard. The fix was never wrong, exactly. It was unverifiable. There was no golden trace that pinned the bad behavior down, so there was nothing to stop it from regressing the moment the input shifted. That is the whole problem this piece is about: a prompt tweak is a hope, and hope does not survive contact with production. A harness does.
I run an ML platform for a legal-tech shop, which means my job is mostly saying no to things that look fine in a demo. Agents made that job louder, not easier. The model is non-deterministic, the failure modes are subtle, and "it worked when I tried it" is not evidence, it is a vibe. The discipline that fixed this for us is older than agents: treat evals like unit tests, run them in CI, and refuse to deploy when they regress. The novelty is what you put under test. Not a single model output, but a whole agent run: the tools it called, the order it called them in, the intermediate steps, and the final answer. Anthropic's write-up on demystifying agent evals is the clearest statement of this I have read, and it is where I send people who still think an eval is a spreadsheet of prompts.
What a harness actually is, minus the leaderboard
People hear "eval" and picture a benchmark: a number that goes up, a tweet, a leaderboard rank. That framing is poison for an ops team. A leaderboard tells you that you are better than someone else on a task you do not have. A harness tells you whether your own system still works after the change you just made. Those are different machines. Anthropic defines the eval harness as "the infrastructure that runs evals end-to-end: it provides instructions and tools, runs tasks concurrently, records all the steps, grades outputs, and aggregates results." Read that again and notice what is missing. There is no ranking. There is plumbing. The harness is rejection infrastructure, and the sooner you stop treating it as a scoreboard, the sooner it earns its keep.
One more thing from the same source that changed how my team talks: when you evaluate "an agent," you are not evaluating the model. You are evaluating the harness and the model working together. The scaffold, the tool definitions, the retry logic, the prompt: all of it is under test at once. That is why swapping a model version is not a config change in our shop, it is a deploy that has to clear the gate like any other.
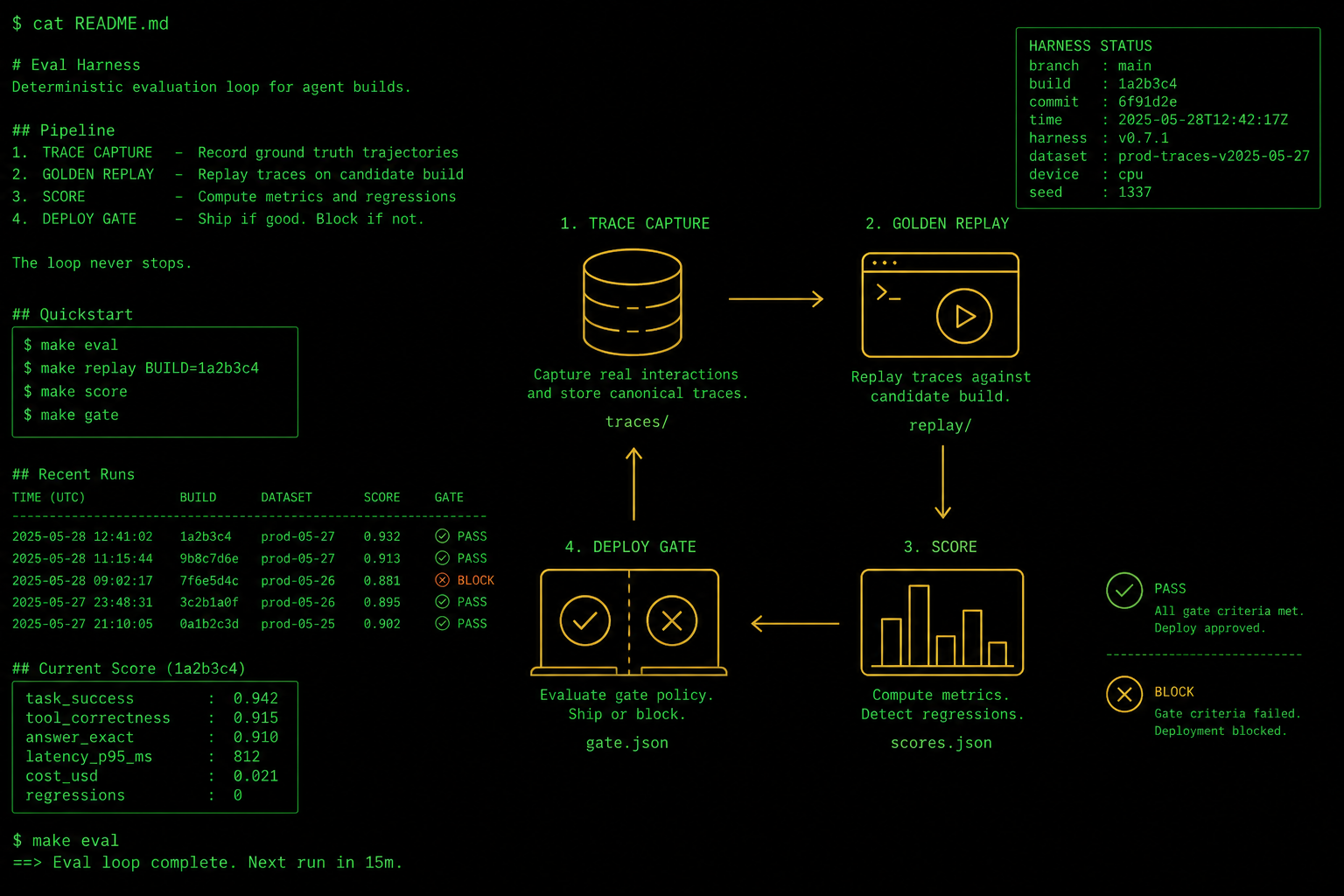
Figure 1 · the loop
trace → eval → gate → ship → trace
Step 1
Capture the trace, then mine it for failures
You cannot evaluate what you did not record. So before any of the scoring matters, instrument the agent to log the entire run: the input, every tool call with its arguments, the intermediate reasoning steps, the final output, plus latency and token counts because finance will ask. A trace is not a log line. It is the full replayable history of one task. Once you have traces flowing, the gold is hiding in the failures. LangChain put it in a line I have stolen for every onboarding doc: "a trace where the agent made a mistake is an eval case, and a trace where a user corrected the agent is even better." Their recipe for harness hill-climbing walks the whole flywheel, but that one sentence is the engine.
In practice this means your eval suite is not authored, it is harvested. When a paralegal flags a bad summary, that run becomes a golden trace. When a user edits the agent's answer, the corrected version becomes the expected output. The suite grows out of real failures instead of the failures a tired engineer imagined on a Tuesday. That is the difference between an eval set that catches your actual bugs and one that catches bugs you already knew about.
02 · Stub the world so CI stays deterministic
Here is where most teams stall. A golden trace that calls a live API is not a test, it is a flake generator. The upstream service rate-limits you, returns yesterday's data, or goes down during your release window, and now your gate is red for reasons that have nothing to do with the agent. The fix is boring and non-negotiable: replay golden traces against stubbed tools and mocked APIs. The recorded trace already contains what the tool returned the first time, so feed that back. The agent runs against a frozen world, the same inputs produce the same scoreable run, and CI stops lying to you.
This is also where the eval harness and the production harness have to be the same scaffold, not cousins. If your CI agent uses different retry logic, a different tool router, or a stale prompt template, you are testing a system you do not ship. Pin them together. We run the identical agent code in CI and prod, and the only thing that changes is whether the tools are real or replayed. If that sounds like overkill, it is cheaper than the Monday I described at the top.
Figure 2 · scoring
deterministic checks under the judge
The gate is the only opinion that ships
Everything above is setup for one decision: does this build deploy or not. The regression gate is where eval stops being observability and becomes infrastructure with teeth. The rule is simple and it has to be mechanical. Run the golden suite against the candidate build, aggregate the scores, and compare to a pinned baseline. If the score drops below the baseline by more than your tolerance, block the deploy. No override-by-Slack-message, no "it's probably fine," no shipping on a Friday because the on-call wants their weekend. The gate does not have feelings. That is its entire value.
Here is the shape we run, stripped to the spine. It is pseudocode, not a framework pitch, because the logic is what matters and the logic is small.
# Regression gate: golden traces in, deploy decision out
EPSILON = 0.03 # tolerated score drop vs pinned baseline
def gate(candidate_harness, golden_suite, baseline):
results = []
for trace in golden_suite: # golden_traces.jsonl
run = replay(candidate_harness, trace.inputs) # stubbed tools
results.append(score(run, trace.expected))
current = aggregate(results) # mean pass-rate or weighted score
if current < baseline - EPSILON:
block_deploy(reason=f"regression: {current:.3f} < {baseline:.3f}")
return False
ship() # deploy the candidate
append_passing(results, golden_suite) # passing runs grow the suite
return True
Two details earn their place. The EPSILON tolerance keeps judge noise from blocking on a meaningless 0.5 percent wobble, and you tune it down as your scorers get more stable. The append_passing step is the flywheel closing: every clean release feeds its traces back into the suite, so the gate gets stricter as the system gets more coverage. The harness you build in week one is not the harness you run in month six, and that is the point.
Figure 3 · the gate
one decision, two exits
Where this bites back: the judge drifts
I would be selling you something if I pretended the LLM-as-judge layer is trustworthy on its own. It is not. Judge scorers drift across model versions, they can be gamed by an agent that learns to write confident-sounding garbage, and they will happily rate two contradictory answers as both excellent on different days. If your gate leans entirely on a judge, you have built a regression suite that regresses itself. This is the honest weak point of the whole approach, and the mitigation is the layering from Figure 2: anchor the gate on deterministic structural checks that cannot be charmed, and treat the judge as a tiebreaker for quality, never as the sole arbiter of pass or fail.
The other failure is quieter and worse: overfitting the harness to its own suite. If you only ever mine the same ten traces, you climb a hill that is not the mountain. The agent gets great at your test cases and stays mediocre at production. The defense is constant trace mining plus periodic manual review of real runs, the unglamorous habit LangChain keeps hammering and the one that actually keeps an eval suite honest. An eval suite you never refresh is a unit test you wrote once and then deleted the assertions from.
The honest tradeoff
A harness is upfront cost. For a weekend prototype it is absurd overhead, and I will not pretend otherwise. The moment the agent touches something a customer or a regulator cares about, the math flips hard: the cost of building the gate is one engineer-week, and the cost of skipping it is the incident you explain to legal. Match the rigor to the blast radius, not to your enthusiasm.
Figure 4 · day one
start with ten traces, not a perfect dataset
Why this is a maturity line, not a tooling choice
The teams that gate on evals and the teams that iterate on prompt vibes are not at different points on the same road. They are doing different jobs. One ships changes it can defend; the other ships changes it can describe. If you are mapping where your own practice sits, the levels of agentic engineering piece is worth a look for the maturity framing, because eval-gated iteration is one of the cleaner lines between hobby and platform.
There is also a tidy connection to the boundary work. A tool contract guarantees a call is well-formed; it cannot tell you the call was wise. A golden-trace regression catches exactly that gap, the agent that passes schema validation and still does the wrong thing, which is why the tool contracts blueprint is an interesting companion read for the failures a schema waves through. Contracts and evals are two machines, and you want both running.
And if the whole framing here, that a harness is rejection infrastructure, sounds familiar, it should. Saying no in a structured, repeatable, blameless way is the entire job. The argument for treating "no" as a feature rather than friction is laid out in scaling your no, and it is worth a read for anyone who keeps getting pressured to ship past a red gate. The gate is not the obstacle. The gate is the product.
Stop tweaking the prompt and hoping. Record the run, mine the failures into golden traces, stub the world so CI is deterministic, score with deterministic checks under the judge, and gate the deploy on a pinned baseline with no manual override. The prompt was never going to remember Monday's bug. The harness will.
Comments (4)
Join the discussion
Sign in to comment, bookmark threads, and continue lessons across sessions.