The interview was going well until it was not. I had spent weeks preparing to talk about the agent I shipped, the one with the eval traces and the multi-step tool calls I was so proud of, and the hiring manager at a healthcare nonprofit listened politely and then asked a question I had never once considered. "When the agent answers a clinical question, where does the patient data go?" I started to say something about the model provider and stopped, because I realized I did not actually know. Did the document get sent to a third-party API? Where were the embeddings stored? Could anyone outside the building, or outside the country, read the contents of a query? I had built a working agent and I could not answer the first question a regulated employer cared about. I did not get that job. I did get an education, and this is me writing it down while it is still fresh, because the thing I was missing was not a tool or a framework. It was an entire layer of the system I had never been taught to see.
So let me state the thing I now believe, plainly enough that you can disagree with it: self-hosted agents win in regulated enterprises when control over the data plane outweighs the convenience of a hosted API. That is not a moral claim about cloud being bad. It is an honest tradeoff, and for a long time I only understood one side of it. I knew that a hosted API gets you to a demo in an afternoon. I did not know that the same convenience quietly decides where your customer's data lives, who has legal access to it, and whether you can even answer an auditor. I am a career switcher, not a compliance officer, so I am going to walk through what I taught myself the way I wish someone had walked me through it, with the sources I leaned on, and with the parts I am still unsure about flagged honestly.
PostureThree deployment postures, and what each one costs you
The first thing that clicked was that "where does the agent run" is not one question but a spectrum with three named points on it: SaaS, self-hosted, and hybrid. I had only ever built the first kind. A SaaS agent platform is the fastest path to value, and that is a real virtue, not a consolation prize. You sign up, you get a key, your data flows to the vendor, and you ship. The problem is what the speed hides. The deployment matrix from Digital Applied scores SaaS at 3 out of 5 on data residency, and the reason it is not lower is that many vendors do offer regional hosting. The reason it is not higher is the part I had never heard of: if the vendor is a US-parent company, your data can sit under the reach of the US CLOUD Act regardless of which region the servers are in. For a European healthcare nonprofit, that is not a footnote. That is a disqualifier.
Self-hosted sits at the other end, scored 5 out of 5 on residency in the same matrix, because the data physically never leaves infrastructure you control. You run the agent runtime, the retrieval store, and ideally the model itself inside your own virtual private cloud or sovereign environment. The cost is equally real and I will not pretend otherwise: you now own the operations, the GPUs, the security patching, and the on-call. Hybrid is the middle path the article frames as the pragmatic compromise, and the more I read the more it looked like the answer most serious teams actually pick. I will come back to what hybrid means concretely, because it depends on a distinction I did not have language for yet.
Figure 1 · Deployment scorecard
SaaS, self-hosted, and hybrid against the questions an auditor asks
What I had wrong: I treated deployment as an ops detail to figure out after the agent worked. What I learned: deployment posture decides residency, and residency is a requirement that exists before the first line of agent code. What I would do now: ask which posture a job or a project demands before designing anything, because retrofitting a SaaS agent into a sovereign environment is a rebuild, not a config change.
Control plane, data plane, and the line that finally made sense
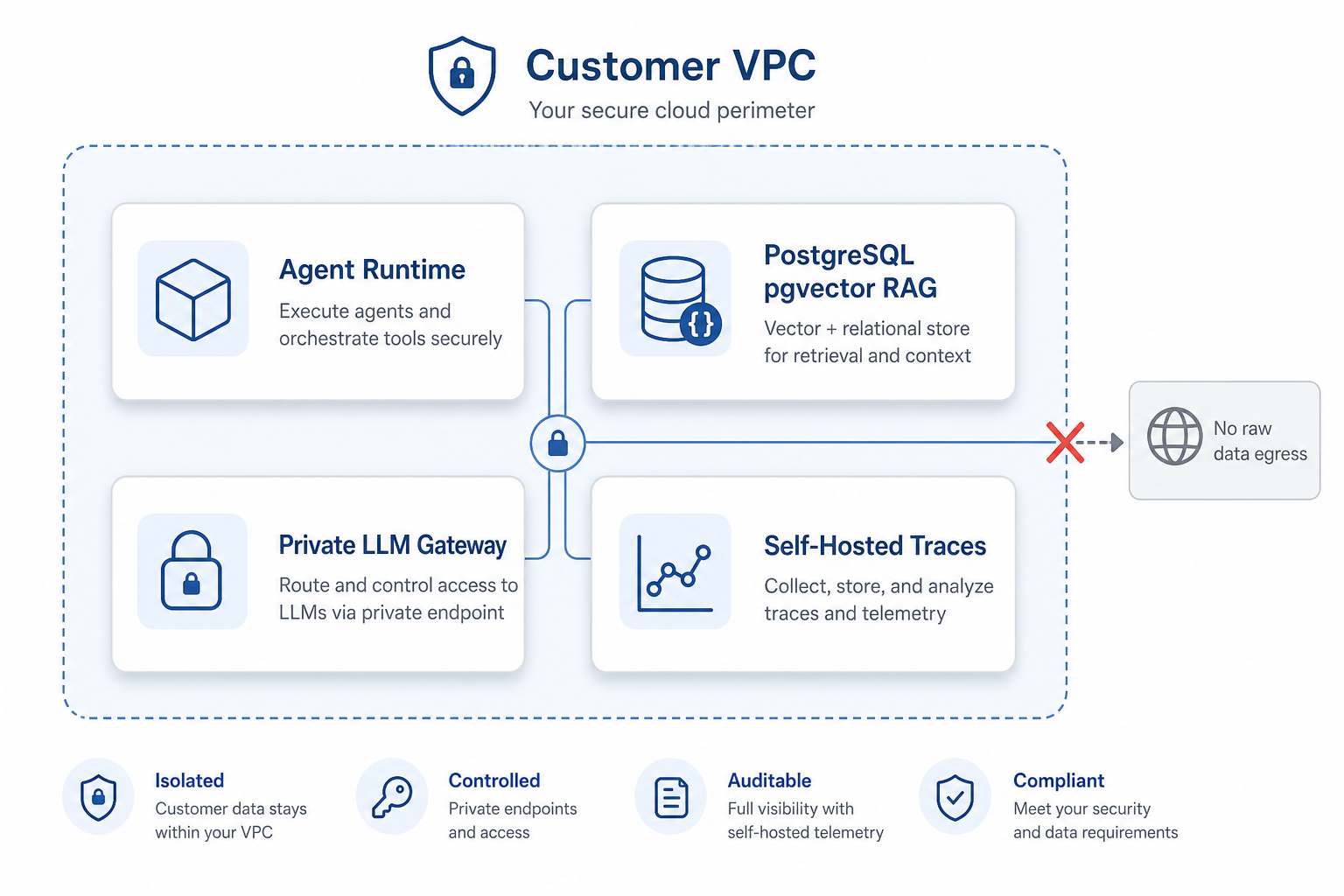
The phrase that unlocked hybrid for me was the split between the control plane and the data plane. I had heard "data plane" before and assumed it was networking jargon I could skip. It is the single most useful concept in this whole topic. The control plane is the management layer: the dashboards, the configuration, the orchestration settings, the place you click to deploy a new agent version. The data plane is where the actual sensitive payload moves: the patient record, the query, the retrieved documents, the model's response, the trace of what happened. Digital Applied describes the hybrid pattern as keeping the control plane in the vendor's region while the data plane runs inside the customer VPC, so that, in their words, no raw customer data ever leaves the customer perimeter.
Once I saw that line, the whole interview question reorganized itself. The hiring manager was not asking about my orchestration framework. They were asking which plane the patient data lived in. A vendor can manage your agent's configuration from anywhere on earth and it changes nothing about compliance, as long as the document and the embedding and the answer all stay behind your boundary. That is why hybrid scores a 4 and not a 3: you accept a managed control plane for the operational ease, and you keep the data plane sovereign for the compliance. The trick, and the part I would want to verify carefully on any real system, is making sure no telemetry or "helpful" debug feature quietly ferries data-plane content up to the control plane without you noticing.
Figure 2 · The plane split
Manage from the vendor region, keep the data inside your perimeter
The deadlineAugust 2, 2026 is a real date on a real calendar
I want to be careful here, because I am not a lawyer and this is the part where I am most aware of the edges of what I know. But the date is concrete enough that I think every junior engineer aiming at regulated work should have it memorized. Digital Applied flags August 2, 2026 as the point at which the high-risk obligations of the EU AI Act become enforceable, with penalties that can reach 7% of global turnover. That second number is what makes compliance teams move. A 7% of global revenue penalty is not a fine a large company absorbs as a cost of doing business. It is an existential number, and it is why the data-residency question I fumbled is suddenly being asked in interviews for jobs that, a year ago, would not have mentioned it.
The obligations themselves are not exotic, and that surprised me. They are the things a careful engineer would want anyway: risk management, event logging, human oversight, and post-market monitoring, all operational before the deadline rather than promised after it. What deployment posture changes is whether you can actually deliver them. This is where I found the LangChain writeup on LangSmith and the EU AI Act genuinely clarifying. Their point is that for EU data-residency requirements, the deployment model of even your observability tooling matters. A self-hosted or bring-your-own-cloud LangSmith keeps trace data inside the customer perimeter, so that, as they put it, your data never leaves your perimeter. I had thought of tracing as a developer convenience. It turns out your traces are a copy of your data plane, and if they ship to a vendor region, you have moved sensitive content out of the boundary through the back door without ever touching the agent itself.
That reframed observability for me entirely. The trace is not metadata; it is potentially the full prompt, the retrieved document, and the model's answer, sitting in a second system. Whoever holds the traces holds the data. So "where do the traces live" belongs in the residency conversation right next to "where does the model run," and it is exactly the kind of thing I would now check before, not after, picking an observability stack. The detail of how to instrument without quietly exfiltrating content is its own topic, and the practitioners who write about observability for agent systems treat content capture as a deliberate, default-off decision for precisely this reason.
What a self-hosted stack actually contains
For a while, "self-hosted agent" was an intimidating phrase that I treated as a single mysterious blob. Breaking it into layers is what made it feel buildable, even for someone at my level. The stack the source material lays out is four layers, all inside the customer VPC, and once I drew it I realized I had used or read about every single piece in isolation. The agent runtime is just your orchestration code running in Docker or Kubernetes, the same containers I already knew. The retrieval and memory layer is PostgreSQL with the pgvector extension, which is a normal database I can run locally, doing double duty as both the vector store and the relational store. The model access layer is either a local open-weight model served by something like Ollama or vLLM, or a private gateway to an API that has been contractually and network-locked to your boundary. And the traces, as I just learned the hard way, are a self-hosted OpenTelemetry or LangSmith deployment so the telemetry stays inside too.
Figure 3 · The self-hosted stack
Four layers, all behind one perimeter
What I had wrong: I assumed self-hosting meant building everything from scratch with a research budget. What I learned: it is mostly assembling components I already recognized, with the boundary as the design constraint rather than an afterthought. What I would do now: stand up exactly this stack as a portfolio project, because being able to say "I ran the agent, the pgvector store, the model, and the traces inside one VPC" is the answer I could not give in that interview.
Going all the way: air-gapped, and what it honestly costs
At the far end of the spectrum is the air-gapped deployment, where there is no third-party egress at all because there is no external connection to leak through. This is the posture for defense, classified work, and the most sensitive healthcare and financial environments. The pieces exist and they are open source. Ontheia describes itself as an MCP-native platform that is GDPR-by-architecture, with row-level security per user so data isolation is enforced at the database rather than bolted on in application code. Their framing of the problem is the bluntest version of the thesis I have read: every time you send a company document to a cloud AI, your data leaves your building. SecureYeoman takes a similar sovereign posture, layering Open Policy Agent governance and audit trails on top. And for retrieval specifically, Onyx is built to run fully air-gapped, which is why it shows up on shortlists for environments where connecting to a hosted API is simply not allowed.
I would be doing exactly what I am trying not to do, though, if I sold this as free. The counterpoints are real and a junior engineer who pretends otherwise will get caught out in the same way I got caught out on residency. First, total cost of ownership. Self-hosting moves the bill from a per-token API line item to GPUs, operations staff, security patching, and on-call rotations, and for many teams the hybrid middle ground exists precisely because full self-hosting is expensive to run well. Second, model quality. The local open-weight models you can run air-gapped may lag the frontier hosted models in raw capability, so you are sometimes trading answer quality for privacy, and that tradeoff has to be made with eyes open rather than assumed away. Third, and this one genuinely surprised me, licensing. Platforms like Ontheia and SecureYeoman use AGPL licenses, which carry obligations that need real legal review before you embed them in a proprietary product. "Open source" does not mean "drop it in and ship." I would not have known to flag that a year ago, and I suspect a lot of people at my level would not either.
If I were prepping for that interview again
I would walk in able to answer five questions in plain language, because these are the ones that actually got asked or that I now know were lurking behind the polite ones:
1. Which deployment posture does this role require, SaaS, self-hosted, or hybrid, and why? 2. Where does the sensitive payload physically live, and does anything cross the perimeter? 3. Where do the traces go, since traces are a copy of the data plane? 4. Is the model local, or a boundary-locked endpoint, and what did we trade for that? 5. What does the EU AI Act August 2026 deadline change for this system specifically? If I cannot answer one of them, that is the gap to close before the interview, not during it.
The proofThe audit trail compliance teams actually ask for
The last piece I had to internalize is that residency is necessary but not sufficient. Keeping data inside the boundary answers "where," but a compliance team also asks "who touched it, with what tool, and can you prove it." That is the audit trail, and it is where the EU AI Act's event-logging obligation meets day-to-day engineering. The components are concrete: role-based access control so only the right people and agents can act, per-tenant isolation so one customer's data cannot bleed into another's, and tool-call logging so every action an agent takes is recorded with enough fidelity to reconstruct later. Ontheia's row-level security and SecureYeoman's policy-plus-audit posture are both, at bottom, ways of making this trail enforceable rather than aspirational.
Figure 4 · The audit checklist
What turns a sovereign deployment into a provable one
This is also the point where my world connects back to things I had already been studying. The tool-call logging row is not separate from observability; it is the same span and trace data that practitioners write about under agent observability, just read by a compliance lens instead of an on-call one. The boundary around a self-hosted Model Context Protocol server, the auth and the isolation that keep tool access governed, is exactly what the production guide to MCP servers covers in depth. And the managed-cloud contrast, the other side of the SaaS column in my first figure, is laid out in the Google ADK enterprise playbook, where governance and eval gates live inside a vendor's cloud rather than your own VPC. I am increasingly convinced these are not separate topics. They are one topic, the data plane, viewed from different jobs.
What I would tell the version of me in that interview
I would tell her the question was fair, and that the gap it exposed was not a gap in cleverness. I knew how to make an agent work. I did not know how to make an agent that a regulated employer could legally run, and those are genuinely different skills that the prompt courses and the tutorial repos had never mentioned. The fix was not learning a harder framework. It was learning to see the layer I had been ignoring: where the data lives, where the traces go, which plane each piece sits in, and what an auditor would need me to prove. That layer turns out to be where a lot of the actual hiring demand in regulated sectors lives right now, which is encouraging for anyone like me who is still building a portfolio and looking for a way to stand out that is not "I prompted really well."
If you are also breaking into this field, and especially if you are aiming at healthcare, finance, government, or anything touching European users, I would put one self-hosted, boundary-respecting project on your list and treat the data plane as a first-class design constraint from line one. It is the kind of thing I wish I had read before that interview, and it is the natural companion to the broader path I tried to map out in writing about breaking into agentic engineering. I am still learning all of this in public, and I will get details wrong, but I will not get caught flat on that question again. Self-hosted agents trade the convenience of an API for control over the data plane, and once you have stood in a room where someone is responsible for patient records, it is obvious which one they were hired to protect.
A hosted API answers "how fast can we ship." Self-hosting answers "where does the data go." I learned, a little too late for that job, that compliance teams only ever cared about the second question.
Comments (4)
Join the discussion
Sign in to comment, bookmark threads, and continue lessons across sessions.