Ingrid Martinez8/26/2025
Senior Solutions Architect · Agriculturearticle
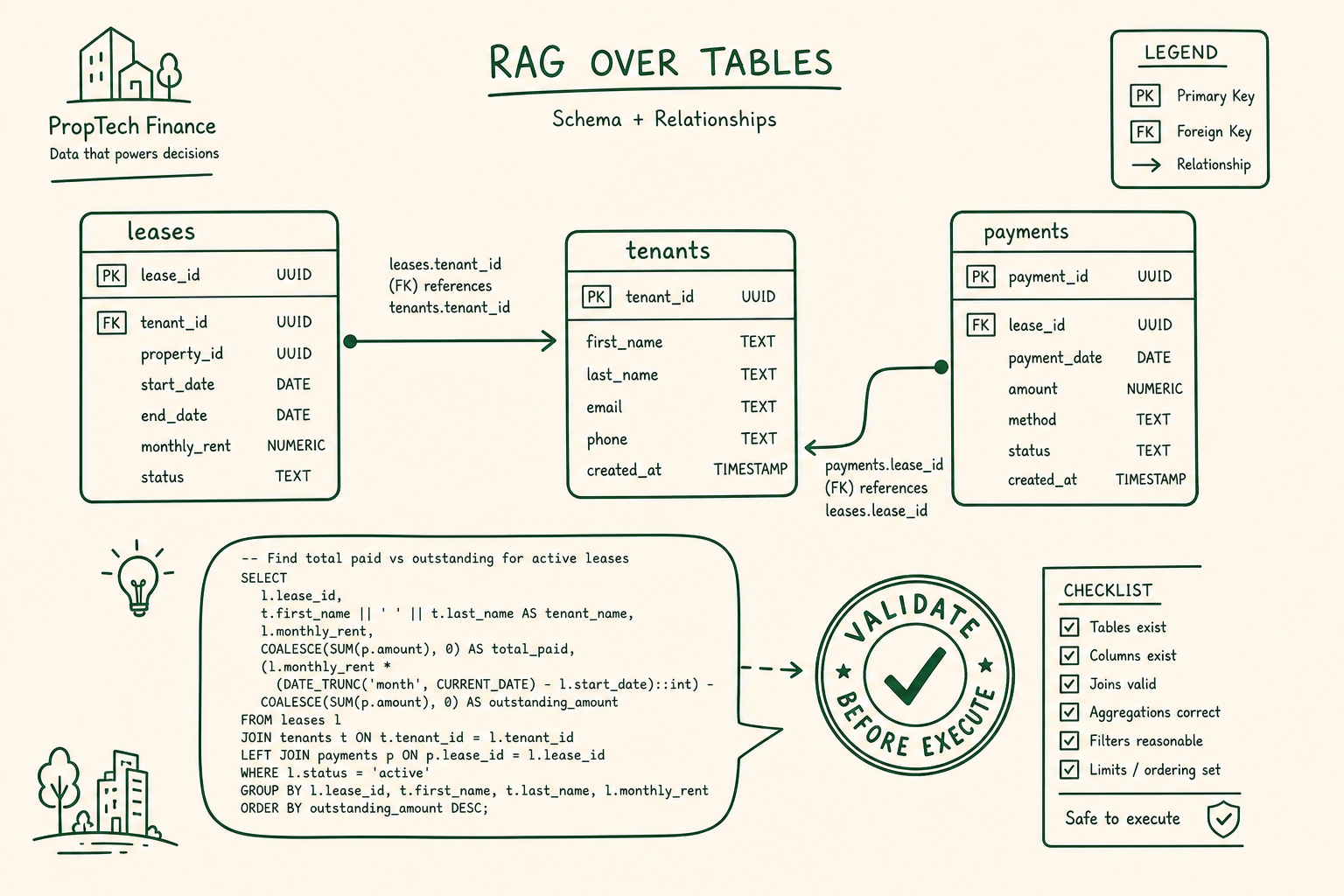
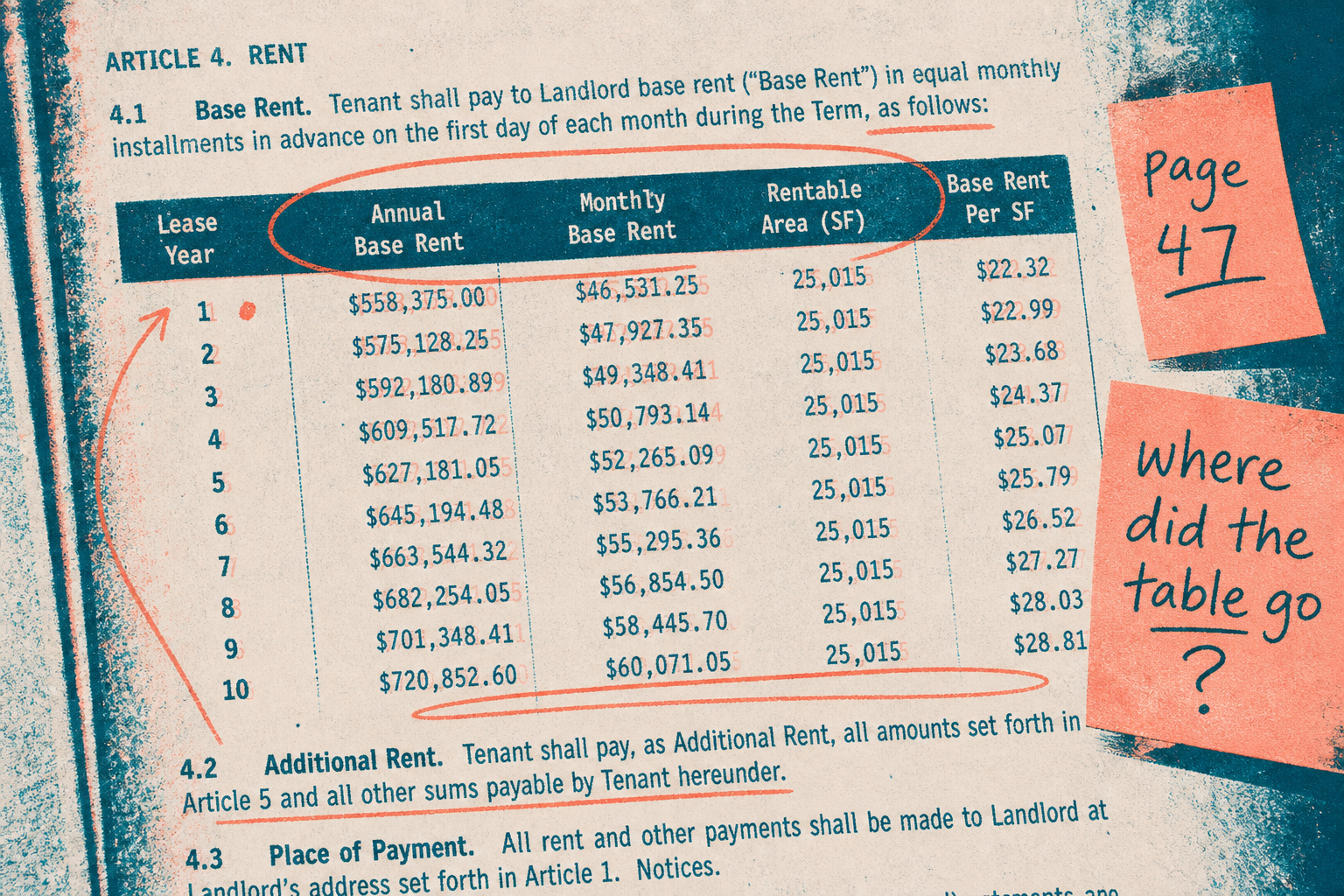
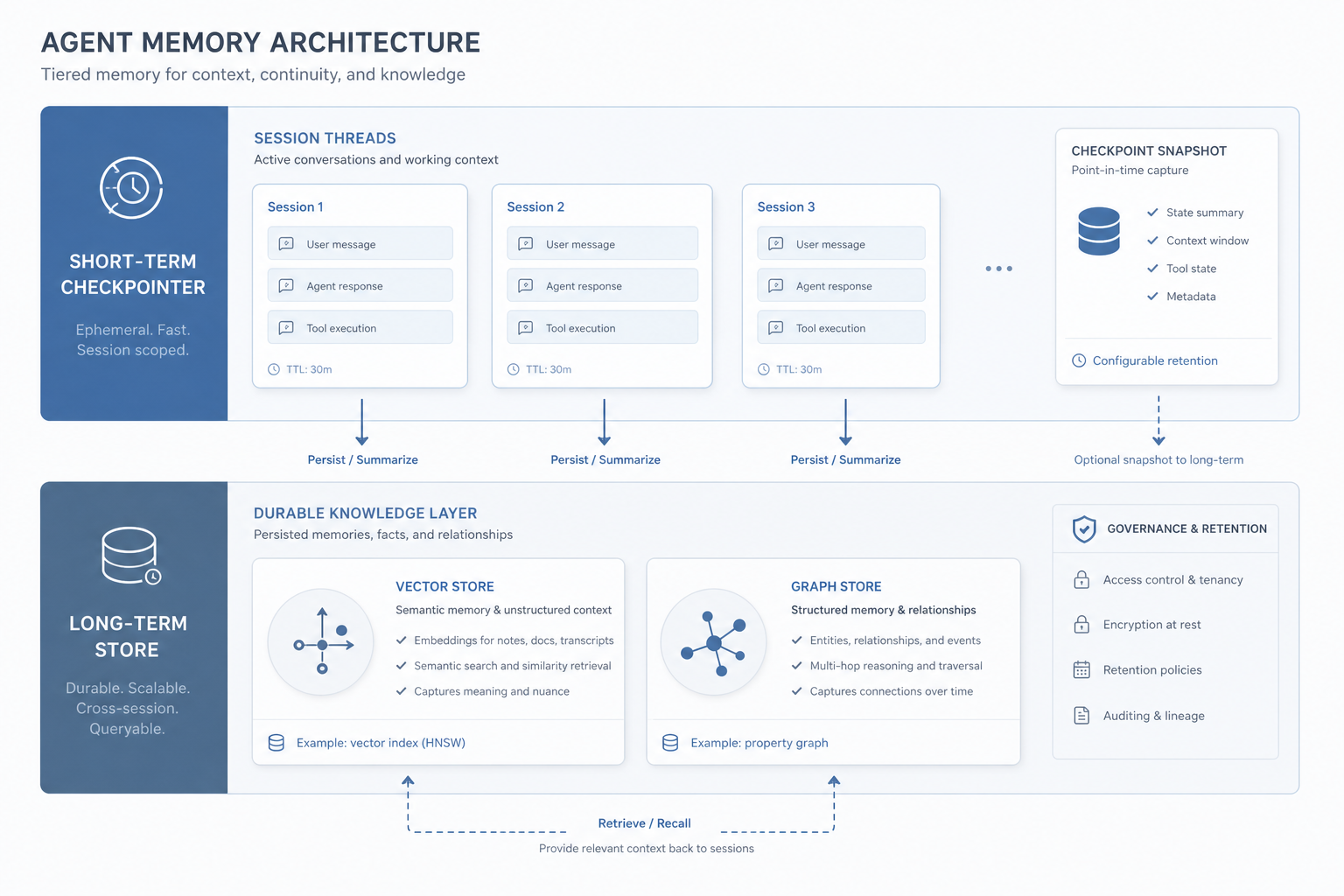
Episodic logs are not structured state.
Short-term scratchpads, long-term knowledge stores, and session boundaries each solve different problems. Treating chat history as memory is why your agent forgets what mattered.