Here is the lesson it took me three rebuilds and one very patient compliance lead to internalize: success in document RAG is decided at the parser, not the embedding model. Layout-aware parsing plus hybrid retrieval beats a fancier vector model almost every time, because parsing decides what is even allowed to enter the index. If the table, the reading order, or the page reference dies during ingestion, no embedding on earth can retrieve a fact that is no longer in the corpus.
I will tell this the way it happened, because the order matters: the war story, then the autopsy, then the fixes that finally held. I am skeptical of anyone who tells you RAG is solved, and I am especially skeptical of the magic-chunk-size advice that shows up under every retrieval thread. Chunk size is a knob. The parser is the engine. Let me show you why.
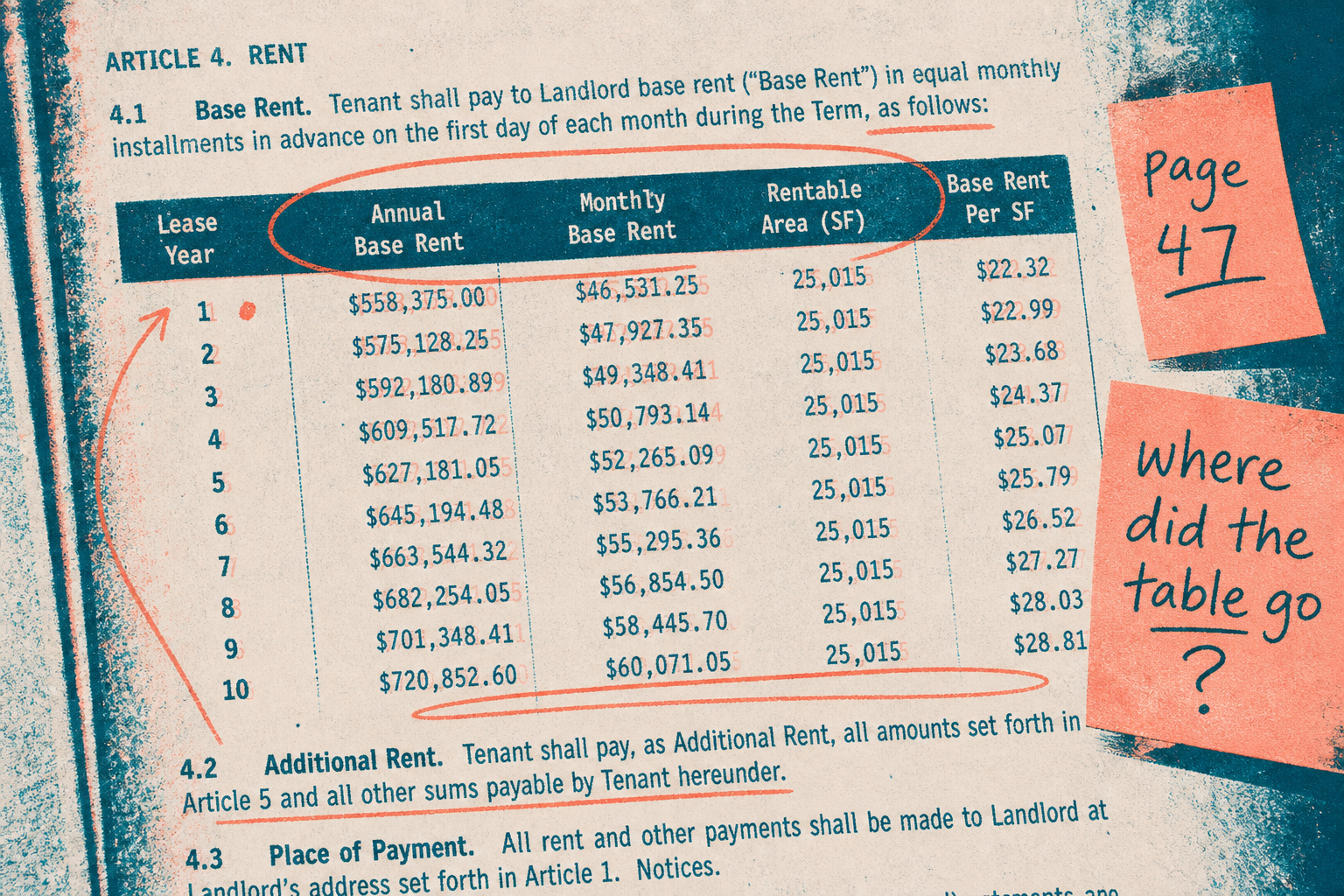
The third pipeline this year died on page 47
The document was a commercial real-estate underwriting packet. Roughly ninety pages: a cover memo, rent rolls, a few scanned pages someone had clearly run through an office scanner at an angle, and the financials. The money lives in the financials, and the financials live in tables. Net operating income, cap rate, debt service coverage, a column of trailing-twelve actuals next to a column of underwriter adjustments. The kind of page where the difference between two adjacent cells is the difference between a deal and a pass.
Our agent answered a question about debt service coverage and confidently cited a number that did not exist on the page. Not a rounding error. A number that was assembled out of two different rows that the parser had flattened into one line. The retrieval looked fine. The recall metric looked fine. The answer was nonsense with a citation stapled to it, which is the most dangerous failure mode there is, because it passes the smell test until an underwriter catches it.
My first instinct, the same wrong instinct I had on the two pipelines before this one, was to blame retrieval. Swap the embedding model. Bump the top-k. Tune the chunk overlap. I spent the better part of a week there before I did the one thing I should have done first, which was to open the parsed output and read what the index was actually holding. Page 47 was not a table anymore. It was a paragraph of digits.
That is the whole genre of bug, and it is why I now have a rule taped to the metaphorical wall: before you touch the embedding model, audit the parse. Read the raw extracted text for your three nastiest documents. If the tables are gone, nothing downstream can save you.
The thing about that failure is that it was not random. It was a predictable cascade, and the research community has a name for it now.
Parsing decides what the retriever is even allowed to find
The cleanest framing I have read on this comes from the 2026 enterprise document RAG writeup at KoreaDeep, which leans on the OHR-Bench work presented at ICCV 2025. The point they hammer, and the one I wish I had absorbed two pipelines ago, is that parsing errors do not stay contained. They cascade. Lose a table, a label, or the reading order during ingestion, and the retriever is now searching distorted evidence even when the language model is excellent.
"Parsing determines what enters the index. If tables, labels, reading order, or page references are lost during ingestion, the retriever searches incomplete or distorted evidence even when the language model is strong." (KoreaDeep, citing OHR-Bench)
Read that twice if you have ever debugged a hallucination by reaching for a bigger model. The model was never the constraint. The academic survey work on document parsing, the arXiv piece catalogued as 2410.21169, frames document parsing as the step that turns unstructured or semi-structured pages into structured, machine-readable representations that downstream retrieval can actually use. When that step is sloppy, you are not doing retrieval over your documents. You are doing retrieval over a lossy photocopy of your documents.
So what does the failure actually look like, side by side? Figure 1 is the before-and-after I now show every new engineer on the team in their first week, because it shortcuts about a month of painful discovery.
Figure 1 · same page, two ingestions
What naive extraction destroys, layout-aware parsing keeps
I want to be fair to the naive extractor for a second. For a clean, single-column memo it is fine, fast, and free. The trouble is that enterprise documents are almost never clean single-column memos. They are invoices, contracts, underwriting packets, regulatory filings, and the occasional handwritten form that someone scanned upside down. As the KoreaDeep piece puts it, once your corpus looks like that, parsing stops being a preprocessing detail and becomes a core architecture decision. I would go further: it is the architecture decision that the others depend on.
The pipeline, honestly drawn
Five stations, and the failures cluster at one of them
Every production document RAG system I have built or inherited is some version of the same five-station line. The Omdena guide to document parsing for RAG lays the stages out cleanly: loading, parsing, chunking, then embedding into a retrievable index, retrieval, and generation. Drawn as a flat list it looks balanced, like each stage carries equal risk. It does not. Figure 2 is the same pipeline with the failure pressure drawn where it actually sits.
Figure 2 · the line, with the pressure marked
A five-station document pipeline, and where the failures enter
Notice what the timeline implies about debugging order. If the damage is injected at station two, then tuning stations four and five is treating symptoms. This is the trap I fell into on page 47, and the reason I now insist on a parsing audit before any retrieval tuning. There is a related point worth making about chunking, station three: the move that helped us most was to stop chunking by fixed token windows and start chunking by structure. A table is a chunk. A section is a chunk. A figure and its caption are one chunk. When the parser hands you semantic element labels, let those drive the boundaries instead of a blind 512-token slice that cuts a table in half.
So which parser do I actually reach for?
This is the question I get in every retrieval thread, and I am wary of answering it as if there is one right tool, because there is not. There is a landscape, and the right pick depends on how weird your documents are, whether you can self-host, and what you do downstream with the output. The Firecrawl roundup of PDF parsers for RAG and the Omdena guide between them cover most of the field. Figure 3 is the matrix I keep in my notes, compressed to the four columns that actually drive the decision.
Figure 3 · the landscape, not a winner
Layout-aware parsers, by what they are actually good at
My honest selection heuristic is boring. If the documents are nasty and the data is sensitive enough that a parsing miss is a compliance problem, I will pay for a managed parser that is good at tables and accept the cloud bill. If I am running high volume on documents I control and ops capacity exists, a self-hosted parser like Docling earns its keep fast. The mistake is reaching for the trendiest option before you have characterized your own corpus. Test your three worst documents through two or three parsers and read the output. The decision usually makes itself in an afternoon, which is less time than I have wasted defending the wrong one in a design review.
With the parse fixed, the next question is retrieval, and here is where I have to talk people down from a different fixation.
Embeddings are not the hero of this story
Once parsing is clean, the temptation is to declare victory on the vector side and move on. The vector model matters, but it is a recall instrument, and recall is only half the job. Vector search is fabulous at semantics, at finding the chunk that means roughly what you asked even when the words differ. It is unreliable at exact terms: a specific clause number, a parcel ID, a property address, a defined term in a contract. Those are precisely the things underwriting and legal queries hinge on, and they are precisely where a pure embedding search will confidently hand you a near-miss.
The fix the field has converged on, and what the KoreaDeep writeup names as the production default for enterprise document RAG in 2026, is hybrid retrieval. Run semantic vector search and a keyword search such as BM25 in parallel, fuse the candidate sets, then put a reranker over the top-k to sort for relevance. Semantic search supplies recall, keyword search supplies the exact-term precision, and the reranker resolves the disagreements. Figure 4 is how I think about that loop, because it really is a loop: each piece covers the failure mode of the piece next to it.
Figure 4 · the loop, not a single knob
Hybrid retrieval: recall, precision, and a referee
One altitude question sits on top of all of this and deserves its own treatment: even with perfect retrieval, how much evidence should you actually push into the model, and at what level of detail? That is a different skill from retrieval mechanics, and if you want the companion argument it is worth setting aside an hour for the breakdown on prompt engineering 2.0, which gets at what should reach the model and what should stay out of the window. Over-stuffing context with marginally relevant chunks is its own way to manufacture a confident wrong answer, even when the parse and the retrieval were both clean.
Instrument the seams, then come argue with me
Here is the discipline that finally made these systems debuggable instead of mysterious: instrument end to end, but fix upstream. Measure retrieval quality, citation accuracy, and faithfulness of the generated answer to the retrieved evidence. Those three tell you whether the system is healthy. But when a metric drops, resist the urge to tune the nearest knob, because the cause is usually further upstream than the symptom. Figure 5 is the cascade I now keep in mind every time a faithfulness number dips, because one parsing miss does not show up in one place. It shows up in four.
Figure 5 · why the symptom is never where the cause is
One missed table, four downstream failures
Now let me argue against my own thesis in good faith, because "parsing first, always" can curdle into its own kind of dogma. There are real counterpoints, and I have been wrong by ignoring them.
Where I temper the thesis
First, full-document layout parsing is not always the cheapest path. For narrow question-and-answer over a fixed field, query-driven selective extraction (sometimes branded as agentic OCR) can pull just the region you need and skip parsing the whole packet, which saves real money. Second, cloud parsers are genuinely expensive at scale; managed table parsing is worth it on sensitive low-volume corpora and a budget line item you will resent on high-volume ones, where a self-hosted parser plus the ops burden is the better trade. Third, embeddings still matter. Parsing fixes precision and structure; recall still rides on a decent vector model. Hybrid retrieval needs both halves to be good, so do not let "the parser is the engine" talk you into neglecting the embedding side entirely.
And there is one structural counterpoint big enough that it deserves its own pointer. Sometimes the honest answer is that a table should not be a chunk at all. If the same financial schema shows up across thousands of documents and people keep asking aggregate questions about it, you are fighting your retrieval layer to do a database's job. For exactly that situation, an interesting read is the writeup on tabular RAG over structured data, which makes the case for when PDF tables should be lifted into relational rows instead of embedded as text. I have shipped both, and knowing which problem you have saves a quarter of thrash.
What I would tell my page-47 self
If I could send one note back to the version of me who spent a week swapping embedding models while the real bug sat in the parsed output: open the index first. Read what your three worst documents actually became after ingestion. If the tables are gone, stop tuning retrieval, because you are polishing a corpus that no longer contains the answer.
The uncomfortable truth of document RAG is that most of the wins are upstream of the part everyone wants to talk about. Fix the parse, chunk by structure, retrieve hybrid, rerank, and cite the page. The model was rarely the problem.
I am not going to tell you RAG is solved, because it is not, and the next packet with a rotated scan and a nested table will humble all of us again. But the failures are legible once you know where to look, and they look the same every time. Audit the parser before the embedding model. Treat the table on page 47 as the prime suspect, not the chunk overlap. Do that, and you will replace far fewer pipelines than I did this year.
Comments (4)
Join the discussion
Sign in to comment, bookmark threads, and continue lessons across sessions.