The page came in as a Slack DM from our CFO at 4:51pm on the last business day of the month, which is the worst possible time to learn anything about money. Three words and a screenshot: "is this right?" The screenshot was the inference line for an agent pipeline we had shipped to a client four weeks earlier. The number was roughly nine times what the proposal had modeled. Nobody had broken anything. Latency was healthy, error rate was flat, the customer was happy with the output. The system was working exactly as designed, and the design was the problem, because every single step in that agent, the planner, the bulk worker, the file mover, the formatter, the little critic that checked the output, all of it called the same frontier model. We had built a Ferrari to deliver pizza, and we were paying Ferrari prices on every block. This piece is about the fix, which is routing, and about why I now treat "what model does each step use" as a first-class architecture question instead of a default someone forgot to change.
I am on call for client agent pipelines, which means I get paged when margin dies, not when a demo looks pretty. That job teaches you a specific kind of cynicism. The thing that ships is rarely the thing that was tested, and the cost model in the proposal is almost never the cost model in production, because the proposal assumed someone would tune the routing and nobody had time. So let me be blunt about the thesis before I justify it: cost control for agents is model routing by task criticality, not uniform frontier usage on every call. If your orchestrator points every step at the strongest model you have, you do not have a cost problem you can optimize away with caching. You have an architecture problem, and the fix lives at the orchestration layer.
Why the bill always surprises you
The trap is that uniform frontier routing is the path of least resistance. You build the agent, you reach for the best model because that is what makes the demo land, and the default propagates to every node in the graph. Nothing in your local testing punishes you for it. You run a dozen tasks, the token counts are small, the dashboard says everything is fine. The punishment is deferred to production volume, where a planner that reasons over a hard problem and a worker that renames a column both bill at the same per-token rate, except the worker runs forty times as often. Cost does not scale with how hard the step is. It scales with how often the step runs times the tier you assigned it, and uniform routing assigns the most expensive tier to your most frequent steps by accident.
The market data on this is not subtle. Zylos Research, in their 2026 model routing writeup, put the headline plainly: "dynamic model routing can reduce inference costs by 40 to 85 percent while maintaining 90 to 95 percent of the quality you would get from the most capable model on every query." Sit with the shape of that. You give up five to ten percent of quality on the margin and you cut the bill by up to five sixths. There is no other lever in agent engineering with that payoff ratio. And yet, in the same report, Zylos notes that "the majority of deployed agents today still hardcode a single model." That is the gap I get paid to close. Everybody knows routing works. Almost nobody has wired it, because it never feels urgent until a CFO sends you three words on a Friday.
Route at the orchestrator, classify before you call
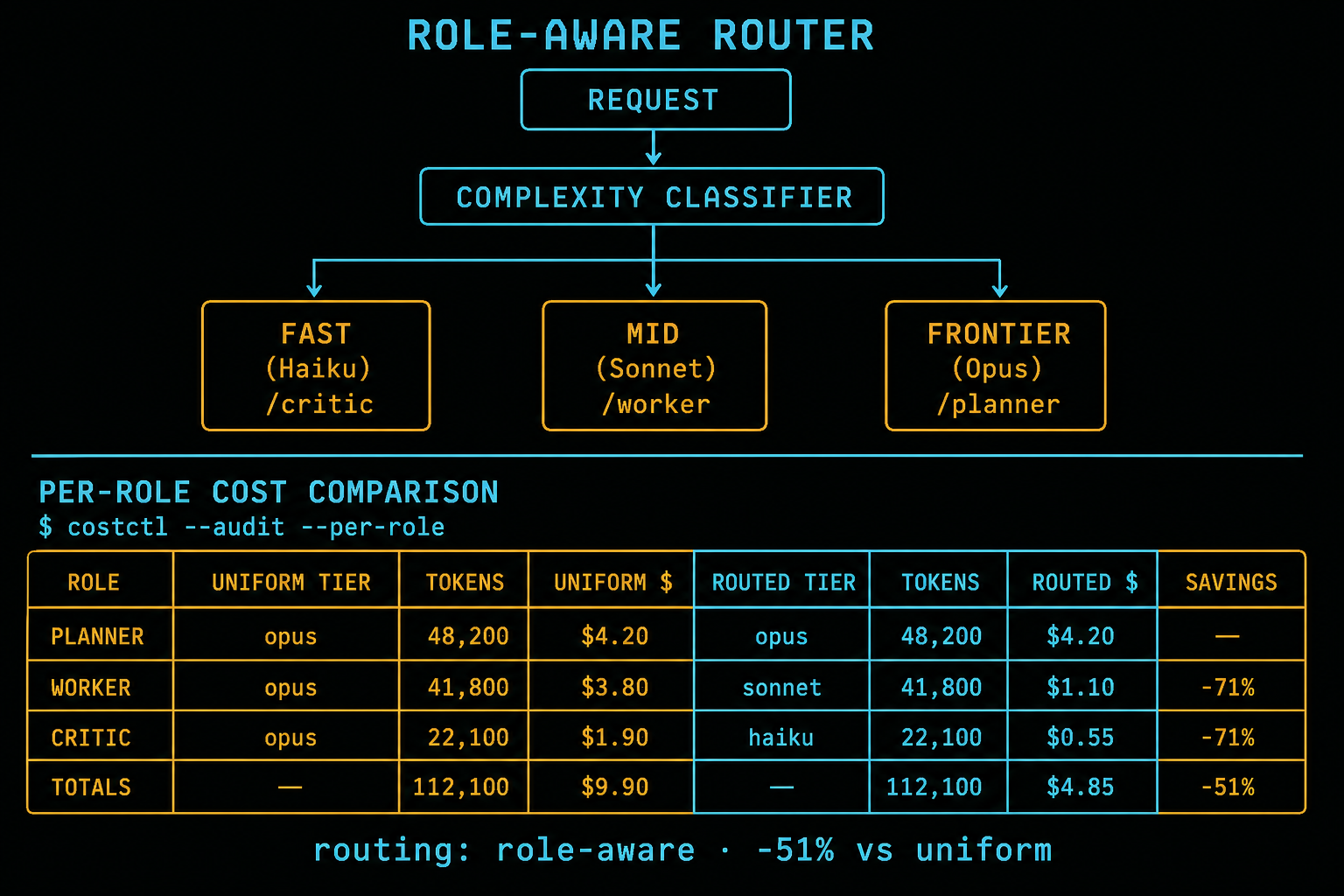
The mechanical version of routing is simple to state and easy to get wrong. Before each LLM call, you decide which tier the call needs. The decision can be a cheap classifier, a set of rules keyed on the agent role, or a learned bandit policy that adapts to feedback. What it must not be is hardcoded into the prompt or scattered across your node definitions, because then you cannot change it without a redeploy and you cannot measure it as one thing. Routing is a policy, and a policy needs to live somewhere you can read it, version it, and tune it. For us that is a thin routing module the orchestrator consults on every call, and the simplest useful version maps complexity to three lanes.
# Agent cost routing stack, conceptual
request -> complexity classifier -> route(policy)
simple -> haiku / gpt-4o-mini # bulk, high frequency
complex -> sonnet / gpt-4.1 # real reasoning, mid frequency
architecture -> opus / o3 # planner only, low frequency
The classifier itself is the thing people overthink. You do not need a learned model on day one. A rule that says "planner role goes frontier, worker role goes mid, file and formatting ops go small" captures most of the savings because role correlates strongly with required reasoning depth. Augment Code, in their routing guide for coding agents, reported that a three-tier Claude setup saved 51 percent against a uniform Opus deployment, which is almost exactly the number my own ledger showed. That is not a coincidence. Coding agents have the same shape as most agents: a small amount of hard planning wrapped around a large amount of mechanical execution. Tier the execution down and the bill collapses without the plan getting dumber.
Figure 1 · tier router
request → classifier → three model lanes
The audit
Tier by role before you tier by anything clever
The first thing I do on a cost engagement is the least glamorous and the highest leverage: I map per-step model usage to per-step necessity. For every role in the graph I ask one question, does this step actually need frontier reasoning, or does it just need to follow instructions reliably. Planner and coordinator roles, the ones that decompose a goal and decide what happens next, those earn the frontier tier because a bad plan poisons everything downstream and the step runs rarely. The bulk implementor, the role that does the repetitive execution the plan hands it, that goes mid-tier, because it needs competence but not genius and it runs constantly. File operations, formatting, schema shuffling, and most review or extraction work goes to the small fast model, because the task is mechanical and the volume is brutal.
This sounds obvious written down. It is not obvious in a running system, because the model assignment is invisible until you go looking. The audit is mostly archaeology: you instrument the pipeline, you attribute tokens per span, and you find the embarrassing truth that 60 percent of your spend is a fast-model task being done by a frontier model out of habit. The savings are sitting in plain sight. Nobody had counted because counting requires per-span attribution, and most teams trace for debugging, not for billing. That is the link between routing and observability, and it is why I will not let a team route blind. If you cannot attribute cost to a role, you cannot route a role, and the observability for agent systems writeup is the prerequisite reading I hand people before any of this, because per-span token metrics are the raw material every routing decision is made of.
The other natural seam here is the planner-worker-critic structure itself. If your agent is already split into those roles, your routing tiers are basically pre-drawn for you, because the roles map cleanly onto criticality. Planner is frontier, worker is mid, critic is usually small or mid depending on how much judgment the review needs. I lean on the same decomposition the planner-worker-critic loops piece lays out, and I treat the tier assignment as a property of the role rather than a property of the call, because roles are stable and individual calls are not. Assign the tier once, at the role, and the routing policy reads like an org chart instead of a pile of conditionals.
Figure 2 · cost attribution
spend by role, not by request
Multi-agent systems need routing that understands collaboration
Role-based tiering gets you most of the way for a single agent. The moment you have multiple agents collaborating, the routing problem grows a second dimension, because now the question is not only which model a role needs but how the agents are collaborating on this particular task and how that should change the allocation. This is where the research has moved fastest. The MasRouter line of work, which Zylos cites, frames multi-agent routing as a pipeline: decide the collaboration mode first, then allocate roles, then select a model per role. The selection is not made in isolation, it is made conditional on the structure of the collaboration, which is the part naive routing misses.
The numbers here are strong enough that I quote them in proposals. CASTER, the context-aware routing approach in arXiv 2601.19793, reports that it "reduces inference cost by up to 72.4 percent compared to strong-model baselines while matching their success rates." Matching success rates, not approximating them. That is the claim that makes routing defensible to a skeptical engineering lead, because the usual fear is that you trade away reliability for cost and end up debugging quality regressions that eat the savings. CASTER's result says the context, the task, and the collaboration structure carry enough signal that you can route aggressively and still land the task. The architecture-level framing of this, treating the model pool as a resource a router schedules work onto, is laid out cleanly in the Workload-Router-Pool paper, arXiv 2603.21354, which is the mental model I use when I explain to a client that their agent is not one app calling one model, it is a workload generator feeding a router that schedules onto a pool of tiers.
The practical caution is that MAS-aware routing is more powerful and more failure-prone. A context-aware router has more ways to be wrong, and a wrong collaboration-mode decision can cascade. I treat the fancy routers as something you graduate into after the role-based version is stable and measured, not something you start with. Earn the 72 percent number by first banking the 51 percent number the boring way.
You cannot route what you do not measure
Every routing policy is a bet, and bets need a scoreboard. The scoreboard is per-span token attribution, ideally over OpenTelemetry so it is not locked to one vendor. Each span carries the role, the tier it was routed to, the tokens in and out, the cost, and a quality signal where you have one. You aggregate those spans by role and you get the table in Figure 2 for free, continuously, in production. More importantly, you get the feedback the router needs to improve. A bandit or learned router is only as good as the reward signal it sees, and the reward signal is cost weighed against quality, both of which come out of the spans. This is the cold-start problem in routing: a learned router has nothing to learn from until traces exist, which is another reason instrumentation comes before cleverness.
The loop I run is span attribution feeding a routing policy that gets evaluated against a quality floor and adjusted, then back to dispatch. When a tier choice produces a quality regression, the spans show it, the policy demotes that route, and the next batch of requests gets the corrected tier. That is the difference between routing as a static config and routing as a control system. The static version saves you money once and then rots as your traffic shifts. The control-system version keeps saving as the workload changes, because it is reading the bill and the quality at the same time and adjusting the dial.
Figure 3 · feedback
OTel spans → routing policy → dispatch
On-call reality
The page that wakes you up will not say "routing is wrong." It will say "quality dropped on tier-3 tasks" or "the bill spiked." Wire your alerts to both axes. A cost alert with no quality alert teaches your router to get cheap and dumb. A quality alert with no cost alert teaches it to get expensive and safe. You want the floor and the ceiling both armed, because a router optimizing one number without the other will happily destroy the other to win.
The counterpoints I make myself say out loud
I would be doing the vibes-without-token-math thing I despise if I sold routing as free, so here are the three failure modes that have actually bitten me. First, the classifier is not free. Every routing decision is a call or a computation that sits in front of your real work, and on a latency-sensitive path a heavy classifier can cost you more in milliseconds than it saves you in dollars. The fix is to keep the classifier cheap, often a small model or pure rules, and to skip classification entirely for roles whose tier is fixed. You do not need to classify the file mover. It is always small. Hardcode that and only classify the genuinely ambiguous steps.
Second, wrong-tier collapse. When the router sends a task that needed frontier reasoning to the fast tier, you do not get a slightly worse answer, you sometimes get a confidently wrong one that the downstream steps trust and build on. This is the failure that scares engineering leads, and they are right to be scared. The mitigation is the quality floor in the feedback loop plus a cheap escalation path: if the small model's output fails a deterministic check, schema, required fields, a confidence threshold, you re-run the step one tier up rather than shipping the bad result. Escalation costs you a retry on the rare miss, which is far cheaper than uniform frontier on every hit. The ROI math only works if you count the retries, and it still wins by a wide margin, which is the kind of denominator-honest accounting the agent ROI PM playbook insists on and I fully endorse, because cost is the denominator of ROI and routing is the cleanest lever you have on it.
Third, compliance can override all of this. Some clients, especially in regulated industries, mandate a specific model for specific data regardless of what your cost optimizer wants. When that is the rule, routing does not disappear, it just gains a hard constraint: certain roles are pinned to certain models and the router optimizes around them. Pretending the constraint is not there does not save money, it gets you a finding in an audit. Build the pin into the policy as a first-class rule and route the unconstrained majority of the workload, which is usually still most of the bill.
What I actually ship on Monday
Strip away the research and the framing and the on-call war stories, and the engagement is a short checklist. Audit per-step model usage and attribute tokens by role, because you cannot fix a bill you have not read. Tier by role first, planner frontier, worker mid, file ops and review small, because role correlates with required reasoning and that captures most of the savings with none of the cleverness. Move the routing decision to the orchestration layer so it is one policy you can version and tune, not a default scattered across nodes. Validate every routing choice against a quality floor using per-span attribution over OpenTelemetry, and arm both a cost alert and a quality alert. Add a cheap escalation path so wrong-tier misses retry up instead of shipping. Only after all of that is stable do you reach for context-aware or learned routers and chase the CASTER-class numbers.
The honest summary is the one I gave my CFO after that Friday page. The agent was never broken. We had just built it to pay frontier prices for janitorial work, and the demo hid the bill because the demo had no volume. Routing fixed it in a week and cut the line by half, not because we found a cheaper vendor but because we stopped using the same model tier on every step. That is the whole lesson. Uniform frontier routing is the most expensive default in agent engineering, it is invisible until production volume makes it visible, and the fix is architecture, not austerity. Route by criticality, measure by span, and the next month-end Slack from finance can be a thumbs up instead of three words and a screenshot.
Audit token spend by role, not by request. Tier the planner to frontier, the worker to mid, the file ops to small, and move the whole decision to the orchestrator where you can version it. Validate with per-span OTel attribution against a quality floor, arm cost and quality alerts together, and add a cheap escalate-on-failure path. The bill was never about the model. It was about using one tier for every job.
Comments (4)
Join the discussion
Sign in to comment, bookmark threads, and continue lessons across sessions.