The best agent demo I saw last year was five agents in a group chat. They argued, they delegated, they self-corrected, and they shipped a working feature on stage to real applause. The same architecture went into a regulated workflow two months later, and the first incident review asked one question nobody could answer: which agent made the write that touched production, and what checked it before it landed? The transcript was a thousand turns of cheerful improv. There was no gate, no single owner of mutation, no record of an approval. The demo was magic. The audit was a shrug. That gap is the whole argument for putting explicit roles around the loop.
I spend most of my week comparing orchestration stacks, and I try hard not to be a fanboy about any of them. So take this as a pattern recommendation, not a framework crusade: the planner, worker, critic loop is the one I default to, and the vendors who run agents at scale tend to agree. TunerLabs, writing up the orchestration patterns it sees most often, is blunt about it: "One thinks. One does. One checks. This is the most-used pattern in our harness and the default unless you have a specific reason to choose something else." That last clause matters. It is a default, not a law, and the rest of this piece is about when the default earns its keep and when it gets in your way.
Who is even allowed to break things?
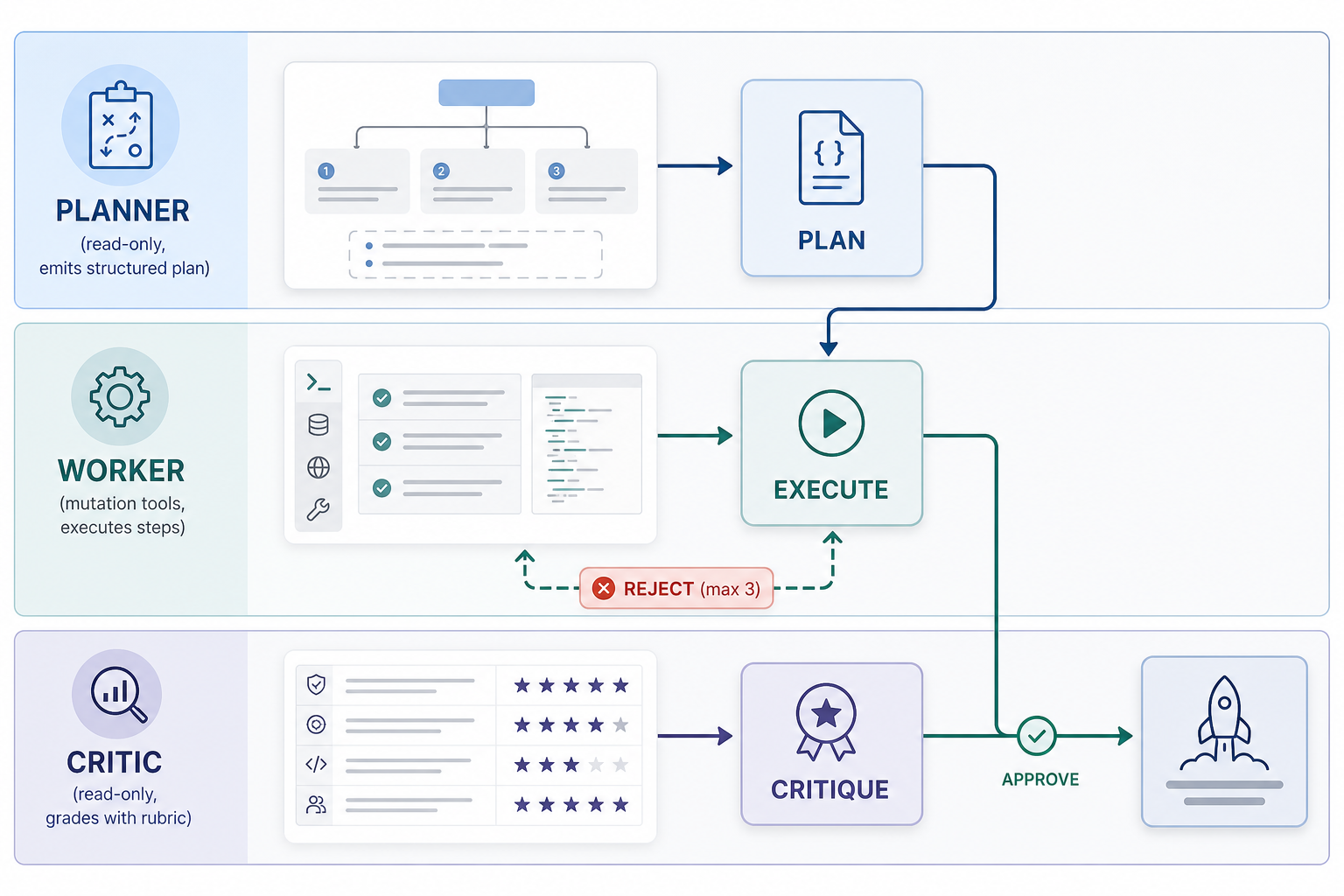
The reason I start here, before any diagram, is blast radius. In an improv crew, any agent can pick up any tool, which means your write surface is every agent times every tool. In a role-typed loop, mutation lives in exactly one place. TunerLabs puts the security case better than I can: "Mutation lives in one agent. Two agents are read-only. The blast radius is the executor's tool surface, no wider." Read that twice if you ship into anything regulated. The planner reasons but cannot touch the world. The critic judges but cannot touch the world. Only the worker holds write-capable tools, so when something goes wrong you have one role to inspect, not a swarm to interrogate.
Figure 1 · The loop
Plan, execute, critique, with a bounded reject loop and two exits
Problem: a flat agent swarm spreads write access and judgment across every participant, so nobody owns the outcome. Constraint: in a regulated workflow you must be able to name the role that mutated state and the gate that approved it. Recommendation: assign roles as a hard contract. Planner emits the plan once, the worker is the only role with mutation tools, and the critic grades against a fixed rubric. If your framework lets any agent grab any tool, you have not built this pattern yet, you have just labeled an improv crew.
The detail that makes the grader trustworthy
Keep the critic in the dark on purpose
Here is the subtle rule that separates a real critic from a rubber stamp, and it is the one I see skipped most: the critic must not see how the worker got there. The Agent Patterns Catalog, in its planner-generator-evaluator writeup, states the isolation flatly: "The Evaluator must never receive the Generator's reasoning trace or scratch context, only the artefact and the rubric." If the critic can read the worker's chain of thought, two bad things happen. It starts grading the intention instead of the output, and the worker learns, implicitly or explicitly, to write a persuasive trace that games the grader. Hide the reasoning, hand over the artefact and the rubric, and the grade is about what was actually produced.
Figure 2 · Role permissions
A capability matrix: read-only planner and critic, mutation isolated to the worker
If you are mapping this against where orchestration sits in your own skill set, governed loops like this are exactly the kind of structure that separates a hobby script from a production system. The maturity ladder from improv agents to governed orchestration is laid out well elsewhere, and the levels of agentic engineering is worth a look if you are trying to place your team on that curve.
The research is converging on the same shape
This is not just vendor folklore. The same delegation pattern keeps showing up in the literature, usually framed as a reasoner-planner supervising an executor so that the messy parts stay quarantined. The Reason-Plan-ReAct work describes a Reasoner-Planner Agent that delegates to Proxy-Execution Agents specifically so that tool errors never pollute the planner's context. That is the same instinct as the permissions matrix, viewed from the context side instead of the security side: the planner reasons in a clean room, the executor takes the hits from flaky tools, and a noisy stack trace in the executor does not corrupt the plan that is steering the whole run. POLARIS pushes the same idea further into typed planning and governed execution if you want a heavier formalization to read alongside it.
Figure 3 · Context isolation
The critic receives the artefact and the rubric, never the reasoning trace
Problem: a critic that sees the worker's reasoning grades intent and becomes trivially gameable. Constraint: the grade has to be a function of the output and the rubric only, so it survives a worker that has learned to sound convincing. Recommendation: isolate the critic's context to the artefact plus the rubric, and route tool noise into the executor so it never reaches the planner. Two different isolation walls, same motive: keep each role's judgment clean of the things that would corrupt it.
Where I stop selling the pattern
Now the honest part, because I promised tradeoffs and not a sales pitch. Three roles mean at least three model calls per unit of work, often more once the reject loop turns. For a simple task, a single-agent ReAct call is faster and cheaper, full stop, and wrapping it in a planner and a critic is just latency you pay for governance you may not need yet. The planner is also a single point of failure: an orchestrator-worker hierarchy concentrates risk in the one role that steers everything, which the agentic AI architecture survey names directly, noting that "coordination failures, such as miscommunication, deadlock, or collusion, remain active research areas." Collusion is the spicy one. If your worker and critic share too much, they can quietly agree to pass each other, which is exactly why the isolation in Figure 3 is load-bearing rather than decorative.
There is also a creativity cost I will not pretend away. Free-form multi-agent debate, where agents argue without a fixed grader, genuinely surfaces solutions a rigid critic loop would reject out of hand. In a research setting that openness is a feature. In a regulated operation it is a liability, and the choice between them is a real engineering decision, not a default. The frameworks make this easy to feel: cyclic, stateful graphs in something like LangGraph lean naturally toward governed loops, while role-based crews in CrewAI make freewheeling collaboration the path of least resistance. Pick the tool whose defaults match the loop you actually want, then make the roles explicit on top.
Figure 4 · Escalation
Cap the repair loop, then hand convergence failures to a human
Problem: a critic that can reject forever will either burn budget in a repair loop or quietly lower its bar to escape one. Constraint: some artefacts genuinely cannot be made to pass, and the system needs an honest way to say so. Recommendation: cap the loop at a small N, increment a counter on every reject, and route convergence failures to a human gate rather than a watered-down approval. The escalation path is not an admission of failure, it is the difference between a system that knows its limits and one that fakes confidence.
The critic is just a structured no
Strip away the diagrams and the critic is doing one thing: saying no in a form the system can act on. Not a vibe, not a soft maybe, but a structured rejection with a reason and a bounded path back to a fix. That is a discipline worth its own essay, and the case for treating rejection as a first-class skill rather than a failure mode is made nicely in the piece on scaling your no, which is an interesting read for anyone trying to make their critic mean something. A loop without a real no is just three agents agreeing with each other politely until something breaks.
If you take one thing from all of this, let it be that orchestration is the actual skill here, not the model choice. The roles, the isolation walls, the bounded loop, the escalation gate: that is the engineering, and it survives whatever model you swap underneath it. For a wider view of where this fits among the other things you are expected to know, it's worth taking a look at the rundown of the agentic engineer's stack, where orchestration earns its place alongside the rest.
An improv crew gives you a great demo and an unanswerable audit. A planner, a worker, and a critic give you a slower run and a sentence you can say out loud: this role made the change, this gate approved it, and here is the loop that caught the rest.
Comments (4)
Join the discussion
Sign in to comment, bookmark threads, and continue lessons across sessions.