A guest tried to change a booking through one of our support agents and got told, politely and confidently, that their non-refundable rate was fully refundable. It was not. We found out from a complaint ticket, not from monitoring, because every dashboard I had was green. Latency was fine. Error rate was zero. Token spend was nominal. The agent had simply been wrong in a way no counter measures, and the trace that proved it was sitting in LangSmith doing nothing, because I had wired tracing and stopped there. The trace store was full. The dataset store was empty. The loop was open. This piece is about closing it, because an open loop is just an expensive log viewer with good marketing.
I run agent pipelines on call for a hospitality platform, which means my year is measured in the gap between "looked fine in the demo" and "a real person is angry at 11pm." Observability tools promise to shrink that gap. Most of them shrink the wrong half: they tell you the system responded in 800 milliseconds, not whether the response was a lie. LangSmith is one of the few that is built to grade the content of a run and not just its vitals, but only if you use all of it. So let me be specific about what "all of it" means, because the marketing page flattens four very different jobs into one logo.
Four products wearing one logo
The clearest framing I have read comes from the QASkills 2026 platform guide, which calls LangSmith "four products in one." That is not a knock, it is the most useful way to think about what you are actually adopting. There is a trace store that records every prompt, output, tool call, and piece of metadata. There is a dataset store that holds curated examples you score against. There is an experiment runner that replays evaluators over a dataset and lets you compare versions side by side. And there is a monitoring dashboard that watches production traffic continuously. By 2026 the tracing is framework-agnostic, so this is not a LangChain-only tax anymore; you can instrument any LLM app and still get the trace store. The mistake I made, and the mistake I see on every team that "has LangSmith," is buying four products and operating one.
The thesis under everything that follows is blunt: the platform is only as good as the traces you feed it, and traces are only worth the disk they sit on if they flow into datasets and back out through evals. LangChain says the quiet part directly in their agent improvement loop writeup: "the loop begins with tracing and returns to tracing. Every evaluator runs on traces. Every annotation is attached to a trace." Read that as an instruction, not a poem. If nothing in your setup returns to the trace, you do not have a loop. You have a drawer.
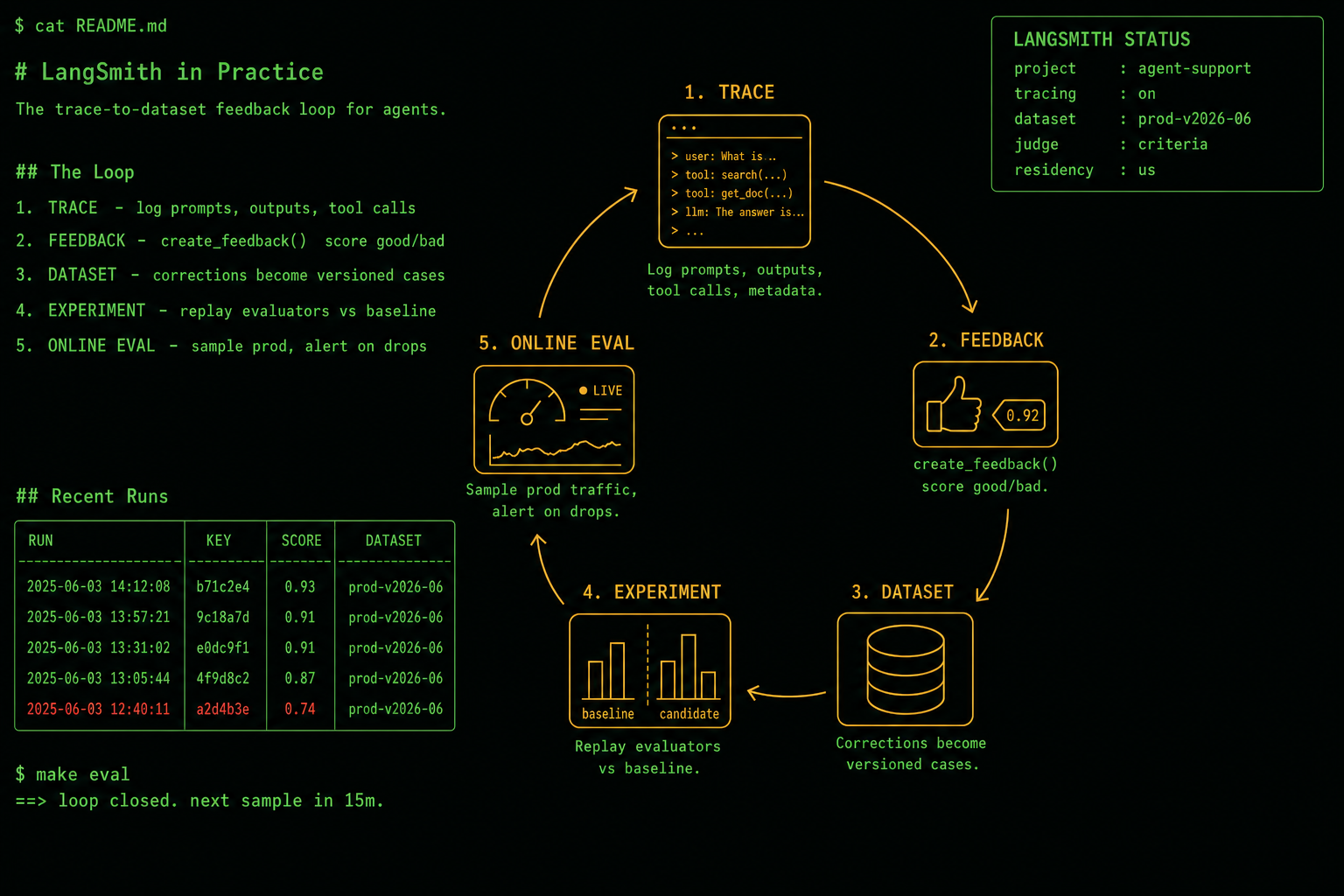
Figure 1 · the loop
trace → feedback → dataset → experiment → online eval
Step 1
Instrument first, because you cannot grade what you did not record
Tracing is the cheapest, highest-leverage thing you will do, and it is almost embarrassingly simple to turn on. Two environment variables and the callbacks start logging prompts, outputs, tool calls, and metadata for every run. That is the whole setup for the trace store.
# Instrument: turn on the trace store
export LANGSMITH_TRACING=true
export LANGSMITH_API_KEY="ls__..." # from the LangSmith UI
export LANGSMITH_PROJECT="agent-support" # buckets your runs
# any LLM app, not just LangChain, can now log runs
Set those and walk away, and within minutes you have the full replayable history of every task: input, each tool call with arguments, intermediate steps, final output, latency, token counts. The trap is stopping here and feeling productive. A full trace store with nothing downstream is exactly the state I was in when the refund incident hit. The traces existed. Nothing read them on a schedule, nothing turned a bad one into a test, and so the same class of error was free to recur until a human caught it by hand. Instrumentation is necessary and nowhere near sufficient.
Capturing feedback is where the loop starts moving
The hinge between "I have logs" and "I have an eval system" is feedback. In LangSmith, feedback is a typed score you attach to a run, and the SDK call for it is create_feedback(). You can attach it to the root run or a child run, hang a numeric or categorical score on it, and crucially you can attach a correction: the answer the agent should have given. That correction is what turns a complaint into a test case. Here is the exact shape I run, adapted from the LangChain feedback SDK docs.
# Attach feedback to a run
from langsmith import Client
client = Client()
client.create_feedback(
run_id=run_id,
key="correctness",
score=0, # negative, so it becomes a candidate eval case
correction={"label": "non-refundable"},
)
# Automation: runs with corrections flow into a dataset (the "Use Corrections" action)
A note that saved me real latency: pass run_id when you have it, but for high-volume background scoring you can submit feedback against a trace_id instead, which lets you log feedback without blocking on the individual run resolving. On a support pipeline doing thousands of runs an hour, that difference is the gap between feedback being free and feedback being a tax on every request. Score the good runs too. As the LangChain classifier docs put it, "any run with positive feedback we can use as a good example in future iterations." Positive feedback is not flattery, it is your regression baseline.
From feedback to versioned datasets, automatically
Doing this by hand does not scale past a week. The piece that makes it durable is LangSmith automations. You set a rule, for example "any run tagged with a correction," and the platform pushes that run into a dataset. The relevant built-in action is "Use Corrections," which takes a corrected run and writes the input plus the corrected output straight into a dataset as a labeled example. Negative-feedback runs with corrections become failure cases. Positive-feedback runs become the examples you must not regress. The datasets are versioned automatically, and every experiment records which dataset version it ran against, so a comparison six weeks from now is reproducible rather than a vibe. This is the step that converted my "drawer of traces" into something an experiment runner could actually spend.
The 3am test
Ask yourself: when a bad run happens at 3am, does anything automatically turn it into a future test, or does it depend on a tired human remembering to file it? If the answer is the human, your loop is open. The "Use Corrections" automation is the difference between an eval suite that grows while you sleep and one that grows only when you have spare attention, which is never.
Offline and online evals are two different jobs
Once datasets exist, evaluation splits into two lanes that people constantly conflate. Offline evals run evaluators (LLM-as-judge, criteria-based, or plain code checks) against a fixed dataset, compare experiments side by side, and answer "did this change make my known cases better or worse." That is the lane you wire into CI as a regression gate, the same golden-trace discipline that the agent eval harness blueprint walks end to end; if you want the gate mechanics in depth it is worth a look, because the mining loop there is the same one I am describing with LangSmith holding the data. Online evals run continuously against a sample of live production traffic, score it as it happens, and alert when the score drops. That is the lane that would have paged me about the refund answer before the guest did.
You want both, and you want them clearly separated, because they fail differently. Offline evals fail by overfitting to a stale dataset. Online evals fail by costing tokens and drifting. Drawing the two lanes explicitly, with the CI gate on one and the alert on the other, is the single diagram that made my team stop arguing about which kind of eval we were "doing."
Figure 2 · two lanes
offline gate vs online watch
Where the bill comes due
I would be doing the works-on-my-laptop thing I despise if I sold you the loop without the costs, so here are the three that bit my team. First, LangSmith is commercial and closed-source. The hosted tier is fine for a lot of shops, but the moment you have a data-residency requirement, and in hospitality you will the moment a European booking touches the system, self-hosting and EU residency live behind the enterprise tiers. Budget for that conversation early, because retrofitting residency is a migration, not a config flag.
Second, LLM-as-judge online evaluators cost tokens and they drift. A judge that scored your traffic at 0.91 last month can score the same traffic at 0.86 this month purely because the judge model changed underneath you, and now you are debugging a regression that was never in your agent. Pair every judge with deterministic checks: schema validation, required-field presence, tool-sequence assertions. Cheap, stable checks anchor the gate; the judge is a tiebreaker for the open-ended quality questions, never the sole arbiter. Same layering discipline as the harness piece, applied to LangSmith's evaluators.
Third, lock-in. The framework-agnostic tracing genuinely eases part of this, because you can point your instrumentation elsewhere without rewriting your app. But your datasets, your automations, and your experiment history live in LangSmith, and that is the part that hurts to leave. If portability matters to you, it is worth comparing the native tracing against open standards; the observability-for-agent-systems writeup gets into OpenTelemetry GenAI versus vendor-native tracing and is a useful read before you commit your whole eval estate to one vendor's dataset format.
Figure 3 · Monday
the five-step wiring checklist
Where LangSmith actually sits
One last bit of orientation, because "should we use LangSmith" usually hides a bigger question about how much of the surrounding stack you are buying with it. The tracing is framework-agnostic now, but the gravity of the datasets, the automations, and the experiment runner still pulls you toward the rest of the ecosystem. If you are trying to figure out where this tool sits relative to LangChain, LangGraph, and the rest of the toolkit before you commit, the langchain ecosystem explainer is an interesting read for placing the pieces, and it will save you from adopting four tools when you meant to adopt one.
The honest summary is the one I give every team that asks me whether LangSmith was worth it. Yes, but not because the tracing is good. The tracing is table stakes and you can get it elsewhere. It is worth it when, and only when, you wire the corrections into datasets and let online evals close the loop. Buy four products, operate four products. Otherwise you have paid for a monitoring dashboard that was green the night a guest got told the wrong thing about their own money.
Turn on tracing in five minutes, then keep going. Score runs with create_feedback and a correction, push corrections into a versioned dataset with the automation, gate deploys on the offline suite, and sample live traffic with online evals so the next bad answer pages you instead of a guest. The trace store was never the product. The closed loop is.
Comments (4)
Join the discussion
Sign in to comment, bookmark threads, and continue lessons across sessions.