Last quarter an agent "succeeded" at filing a support ticket. The run log was green, the model was pleased with itself, and the customer got three identical tickets because the network blipped and the agent retried a non-idempotent call twice. Nobody wrote a buggy prompt. The tool just had no idempotency_key, so the upstream API did exactly what it was told, three times. That is the whole argument of this piece in one incident: the LLM is not where your reliability comes from. The tool boundary is.

I spent years wiring AdTech automation: triggers, retries, dead-letter queues, the unglamorous plumbing that decides whether a pipeline survives a bad Tuesday. Agents are the same job with a fuzzier client. The model is non-deterministic by design, so you do not harden it. You harden the surface it calls. The Model Context Protocol gives you a place to put those guarantees, and a vocabulary for them. The mistake I see most often is treating MCP as a way to "give the agent more tools" instead of a way to constrain what a tool can do and what the model is allowed to learn when it goes wrong.
Figure 1 · the three panes
agent │ mcp server │ upstream api
Server side
What the model never sees
There is a tempting failure mode where you write a paragraph in the system prompt that says "always pass an idempotency key" and "never retry a payment without checking," and you feel like you have done engineering. You have not. You have written a polite request to a stochastic process. The server does not care what the prompt said; it cares what the call contained. So put the guarantee where it is checkable. If a mutating tool requires an idempotency key, the schema rejects the call without one. The agent cannot forget a field that the boundary refuses to accept.
The same logic applies to authorization. Systems Hardening makes the point bluntly in their write-up on MCP auth: any MCP-aware model "can connect to a server, enumerate its capabilities, and invoke tools on the user's behalf." That enumeration is exactly why the server, not the prompt, has to own the answer to "is this caller allowed to do this." Prompts are advice. The boundary is law.
02 · Define the schema, then version it
A tool definition is an interface, so treat it like one. Explicit JSON Schema for inputs and outputs. Tight types, not string for everything. And version the shape, because you will change it: tag schemas v1, v2, and let old agents keep calling the contract they were built against while you migrate. The MCP tools docs spell out the input/output schema model; the discipline of versioning on top of it is yours to add. One more thing the docs hint at and I will say loudly: the tool description is read by the model, so document side effects there. "Creates a ticket. Idempotent on idempotency_key." That sentence is part of the contract, not a comment.
Here is the conceptual shape I reach for. It is not a full server, it is the spine: a typed input, a required idempotency key, and server-side work the model never authors.
// Conceptual MCP tool definition
server.tool(
"create_ticket",
{
title: z.string().max(200),
idempotency_key: z.string().uuid(),
},
async ({ title, idempotency_key }) => {
// server-side authz check + audit log
// dedupe on idempotency_key before any write
return { ticket_id: "..." };
}
);
The idempotency_key is the field that would have saved my three-ticket incident. The agent supplies one key per logical action; the server dedupes on it; a retry becomes a no-op instead of a duplicate. Digital Applied catalogs this and the surrounding enterprise patterns well if you want the wider tour. The point is small and load-bearing: idempotency is a property of the boundary, never of the prompt.
What should the model read when a call fails?
When a tool fails, you get to choose what the agent learns. The wrong choice is to let a raw exception bubble up: a stack trace, a connection string, an internal table name, four hundred lines of framework noise. The model will dutifully try to "fix" things it has no business touching, and you have leaked internals into a context window besides. The right choice is a structured error: a stable code, a short human message, and a retryable flag the agent can actually act on. That is a contract the model can reason about without seeing your plumbing.
Figure 2 · the error surface
what crosses the boundary on failure
retryable: true and a backoff. It can do nothing useful with a Python traceback except hallucinate a fix. Decide your error vocabulary once, keep the codes stable, and let the raw failure stay where it belongs: in your logs.03 · Single bearer, scoped, or capability-based?
Auth is where "more tools" quietly becomes "more blast radius." The common default, and Systems Hardening flags this as the typical deployment, is a single bearer token that grants every tool on the server. It is easy and it is a liability: a prompt-injected agent with that token can reach anything the token can. The comparison below is the figure I pull from their analysis when someone asks why per-tool scopes are worth the setup cost.
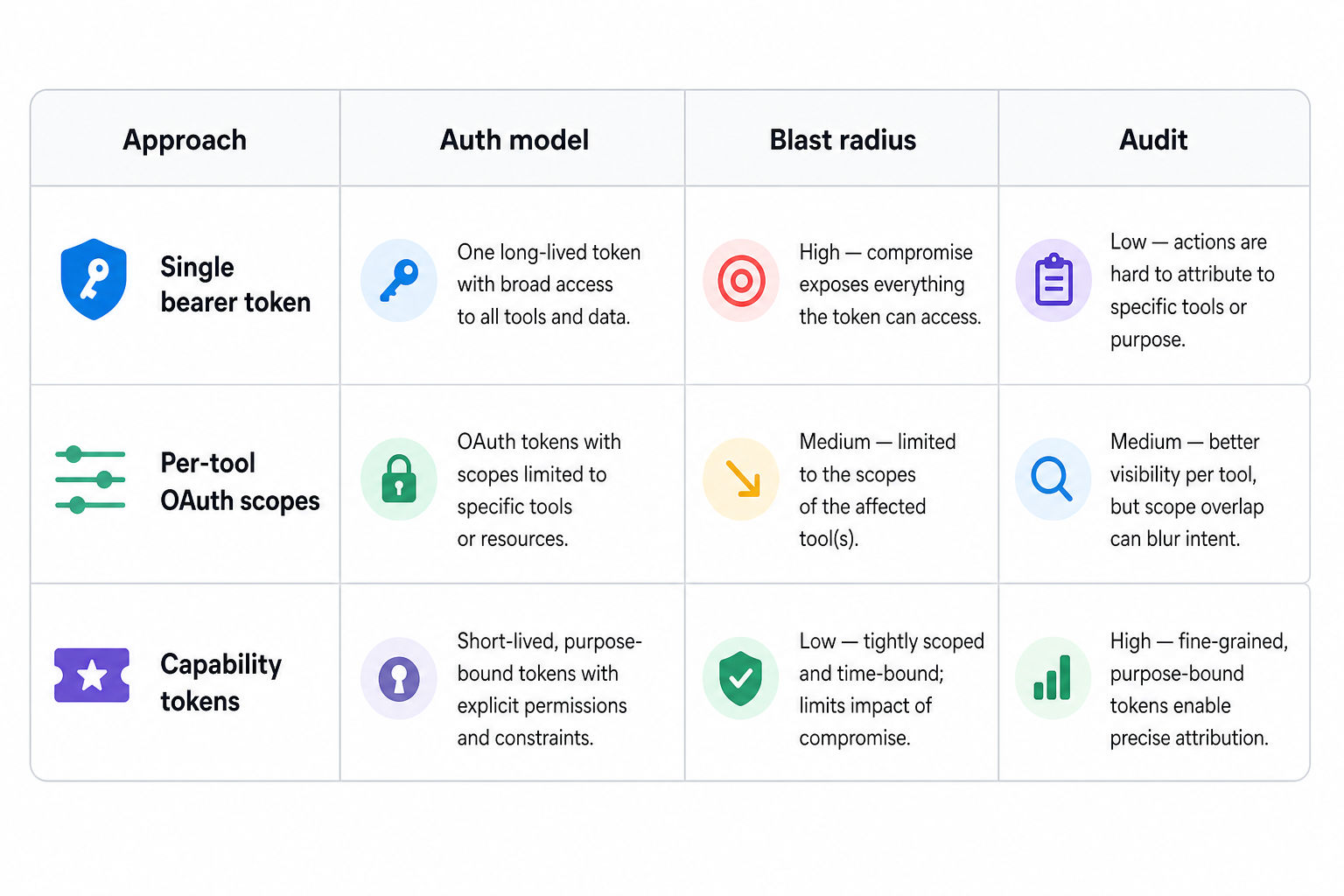
If you have not settled your topology yet (one server per domain, a gateway, how tokens get minted), that is a prerequisite, not a detail. The production auth and topology question is its own piece of work, and the production MCP servers walkthrough is worth a look before you wire scopes onto live tools.
Timeouts and concurrency belong on the server
Here is a place teams write the rule in the prompt and then act surprised. "Do not call this tool more than twice in parallel." The model will ignore that under load, not out of malice but because it is sampling tokens, not running a scheduler. Put the timeout and the concurrency limit on the server, per tool. A slow upstream call gets cut at a deadline you control and returns a clean UPSTREAM_5XX, retryable, instead of hanging the whole run. A burst of calls gets queued or rejected at a limit you set. Clarion AI puts it well in their multi-agent write-up: the tool layer "is what makes the system stateful, where most production failures originate." If that is where the failures live, that is where the limits go.
Figure 3 · scope → tool group
the session only gets the capability it needs
The tripleuser × agent × tool, on every call
When something goes wrong in production, the first question is always "who did this." With agents the honest answer has three parts, and Systems Hardening recommends keying your audit on exactly this triple: which user the action was on behalf of, which agent session made the call, and which tool ran. Log all three on every invocation, with the idempotency key and the structured result. That is what lets you answer "did the agent double-charge this customer" in one query instead of an afternoon of grep.
Figure 4 · the audit triple
one row, three identities, every call
Where contracts stop being enough
I have to be straight about the limits of everything above, because I have watched it lull teams into a false calm. A perfect contract guarantees that a call is well-formed. It guarantees nothing about whether the call was wise. An agent can pass schema validation, hold the right scope, supply a clean idempotency key, and still close the wrong ticket because it misread the user. Contracts catch malformed calls. They do not catch bad judgment. They are necessary and they are not sufficient.
The honest tradeoff
Strict contracts slow down a solo builder shipping an MVP, and that is a real cost. In enterprise, where a wrong call moves money or leaks data, the cost of not having them is higher. Pick the level of rigor your blast radius deserves, not the maximum you can imagine.
The other half of reliability is measuring whether well-formed calls were the right calls, and that is an eval problem, not a schema problem. You need a harness that replays real tasks and scores whether the agent chose correctly, not just whether the server accepted the input. I will not pretend a prompt tweak covers this. If you are designing that measurement layer, the eval harness blueprint is an interesting read for catching the misuse that a contract waves through. Contracts and evals are two different machines, and you want both running.
For the wider map of how tools, skills, and hooks sit as primitives in an agent stack, the Agent Package Manager primitives matrix is a useful frame; it is the zoomed-out version of the single boundary this piece zoomed all the way into. But if you take one thing from me, take the incident: the model did not file three tickets because it was dumb. It filed three tickets because the boundary let it. Fix the boundary.
Stop hardening the model. Harden the surface it calls. Schema rejects the malformed, scope hides the dangerous, idempotency absorbs the retry, structured errors keep your plumbing private, and the audit triple tells you who did what. The prompt was never going to do any of that.
Comments (4)
Join the discussion
Sign in to comment, bookmark threads, and continue lessons across sessions.