I went to Interrupt 2026 expecting to argue about multi-agent architectures, and I left with a notebook full of eval harnesses. That gap, between what the main stage celebrated and what the practitioners actually talked about between sessions, is the most honest thing I can report from two days at The Midway. The thesis of this piece is simple and a little contrarian: the real signal at Interrupt 2026 was reliability and evaluation, even as the keynote energy pushed toward autonomous fleets of agents. If you only watched the highlight reel, you got the hype. If you read the program, you got the roadmap.

I write this as someone who lives in the framework community and ships agents for a living, so take the usual disclaimer: a vendor conference is a vendor's story about the world. I will flag where I think the framing is generous. But the announcements were real, the case studies were specific, and the practitioner consensus was unusually coherent for an event this size.
Interrupt 2026 · the dateline
Two days, a thousand builders, and a program that gave the game away
The numbers, per the Interrupt 2026 recap: two days, more than 1,000 developers, 23 talks, and production case studies from names like Cisco, LinkedIn, Toyota, and Lyft. LangChain's own framing in the May 2026 newsletter was "two days, 1,000+ builders, and what's actually working with agents in production." That phrase, "what's actually working," is the tell. Nobody headlines a conference about what is working unless the prior year was mostly about what was not.
Here is the move I would recommend to anyone reading event coverage: read the program, not the keynote. Keynotes optimize for applause. Session titles optimize for the room a practitioner will actually choose to sit in. And the titles at Interrupt clustered hard. Lyft presented "Building Evals That Actually Matter in Production." Chime presented "Make Legal Write Your Evals." Cisco talked through observing and testing customer-experience agents. None of those are agent-architecture talks. They are evaluation talks wearing enterprise logos.
The product lifecycle LangChain laid out makes the same point structurally. The stack reads as a pipeline that ends, not begins, with evaluation and continuous improvement.
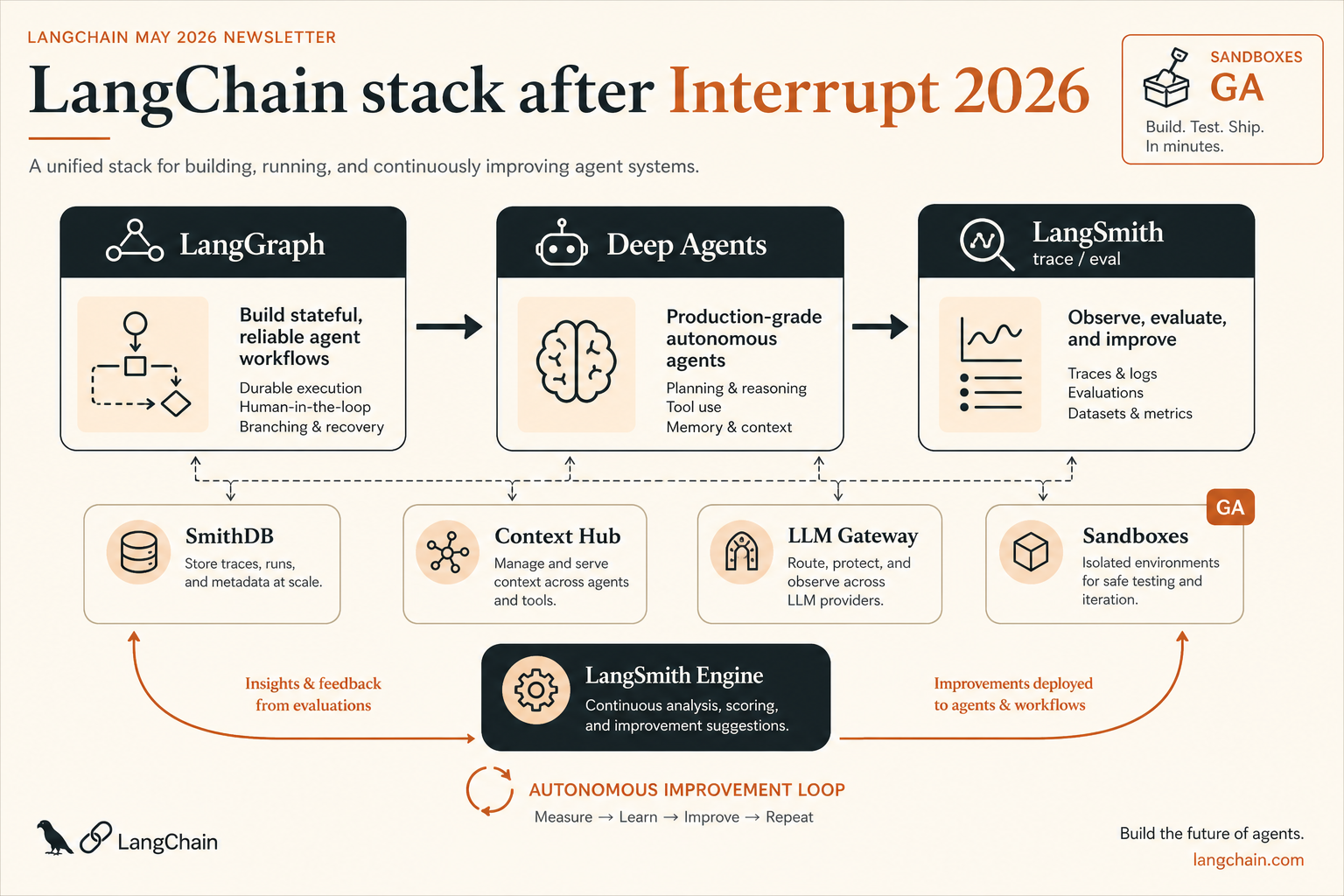
Notice where the weight sits. Orchestration (LangGraph) and execution (Deep Agents) are the parts that get demoed. But the layers getting the most new investment, tracing, evaluation, and the new autonomous improvement loop, all live on the reliability side of the diagram. That is not an accident of layout. It is where the production pain is.
The launches that mattered: Engine and Sandboxes
Two announcements deserve more attention than the multi-agent talk track gave them, because they target the gap between a prototype that works in a demo and a system that holds up under traffic.
The first is LangSmith Engine, now in public beta. The pitch: Engine autonomously monitors traces, clusters failure patterns, and proposes code or prompt fixes. Read that as the manual improvement loop, automated. Today a good team reads traces, spots a recurring failure, writes an eval that captures it, and ships a fix. Engine's claim is that it runs that loop continuously without a human kicking off each turn. LangChain described it as turning "the manual cycle of reading traces, spotting failure patterns, writing evals, and creating fixes into a continuous, automated loop." If it delivers, that is meaningful. It is also a beta, so treat the autonomy claim as a direction, not a guarantee.
The second is quieter and, for regulated teams, arguably bigger: LangSmith Sandboxes reached general availability for running untrusted agent code. GA is the word that matters there. Engine and Managed Deep Agents are still beta, but Sandboxes shipped to a tier you can actually depend on. If your agents generate and execute code, an isolated execution boundary is not a nice-to-have, it is the thing that lets your security team say yes. The infrastructure announcements around it (SmithDB, a Rust trace database described as roughly 15x faster; Context Hub; an LLM Gateway for governance) all point the same direction: the platform is being hardened for scale, not just expanded for features.
Ship tiers, read carefully
Sandboxes are GA. Engine is public beta. Managed Deep Agents is private beta. The further from GA, the more you should discount the production claims. A beta autonomous-fix loop is a research preview with a roadmap, not a thing to wire into your deploy gate this quarter.
The signal split between the stage and the program is worth drawing out, because it is the whole argument of this piece in one frame.
Figure 01 · the signal split
What the stage sold vs. what the program said
Managed Deep Agents, and the part I would discount
The headline architecture launch was Managed Deep Agents, a hosted runtime in private beta offering durable execution and checkpointing for long-horizon agents. The idea is sound: long-running agents need to survive restarts, resume from a known state, and not lose hours of work to a transient failure. Durable execution is genuinely hard to build yourself, and a managed version is attractive.
Here is where I apply the vendor-conference discount. A private-beta hosted runtime is the most speculative thing on the slate, and it is also the thing that creates the most lock-in if you build around it early. Durable execution is a real need, but the managed offering is unproven at GA, and the case studies on stage were not running on it. So I would file Managed Deep Agents under "watch closely, pilot in a sandbox, do not bet a production roadmap on it yet." The maturity gradient matters: Sandboxes earned my trust by shipping GA; Managed Deep Agents has to earn it the same way.
The hallway track was about evals, not agents. The teams that had something working talked about how they measured it, not how many agents they ran.
One more honest caveat about the whole event. A heavy enterprise case-study lineup can quietly overstate how solved reliability actually is. When Lyft and Cisco present polished eval practices, the implied message is "this is a settled discipline now." It is not. Those teams are ahead of the curve, and the curve is still steep for everyone else. Survivorship bias is real at conferences: you hear from the teams whose agents made it to production, not the ones that quietly shelved the project.
So what do you actually do Monday?
If the program is the roadmap, the roadmap is eval-first. Here is the checklist I came home with, ordered so that the cheap, high-leverage moves come before the speculative ones.
Figure 02 · the eval-first Monday list
Four moves, cheapest leverage first
The thing I keep coming back to is the ordering. You do not need LangSmith Engine to start. You need a trace, a failure you can name, and an eval that captures it. That is the discipline Lyft and Chime were really demonstrating, and it is available to a two-person team today with no private beta access required. If you want a deeper build than a checklist, the eval harness blueprint is worth a look for exactly that "evals that actually matter" thesis, laid out as a working gate. And if your reliability work already runs through LangSmith, the LangSmith in practice notes are an interesting read for where Engine extends the trace-to-eval loop you are probably already using.
Where Interrupt sits in the season
Interrupt did not happen in a vacuum. It landed in a 2026 conference season where nearly every major event made some version of the same pivot, from "look what agents can do" to "here is how we keep them honest." That convergence is the real story, and it is bigger than any one vendor's launch slate. For the season in context, the 2026 agent conferences roundup is worth taking a look at to see whether Interrupt's eval-first signal was an outlier or the consensus. My read: consensus, and overdue.
So here is my final, slightly contrarian take, offered as a member of the framework community and not as a LangChain partisan. The multi-agent future may well arrive, and Managed Deep Agents may be part of how it does. But the talks that will age best from Interrupt 2026 are the ones nobody live-tweeted: a Lyft engineer explaining how they decide an eval actually matters, and a Chime team admitting that the people who should write the evals are the lawyers, not the ML team. Reliability is not the boring part of agents. At Interrupt, it was the only part that already worked.
Comments (4)
Join the discussion
Sign in to comment, bookmark threads, and continue lessons across sessions.