Every framework in this space makes the same promise: build agents, fast. Google did something quieter and more interesting. At Cloud NEXT 2025 it took the framework already powering Agentspace and the Customer Engagement Suite, its own production agent surfaces, and put it on GitHub under an open license. The Agent Development Kit is not a research preview or a developer-relations toy. It is the internal tooling, externalized.
That origin explains the design philosophy better than any feature list. The team that built it had to ship agents that survive contact with real users, so the framework reads like something written by people who got paged. The codelab introducing it states the goal plainly: ADK "was designed to make agent development feel more like software development."
I will say this plainly up front, because it is the thesis of the whole piece: ADK's advantage is not any single API. It is that the framework gives you a software engineering lifecycle for agents. Typed primitives instead of prompt spaghetti. Deterministic orchestration where you want control and LLM routing where you want flexibility. A real debugger in the browser. Evals as a first-class artifact. And a deploy story that goes from laptop to managed runtime in one call. By the end of this piece you will have seen every layer, and you will have watched a working enterprise build come together from those layers.
2025
launched at Google Cloud NEXT
v1.0
stable Python SDK since Google I/O 2025
2
SDK languages shipped: Python + Java
3
protocol edges: MCP, A2A, A2UI
The shape of the thing
What ADK actually is
Strip away the branding and ADK is three commitments stacked on top of each other.
Code-first. Agents are Python objects (or TypeScript, Go, or Java objects; the Python SDK is the stable flagship). You define an agent the way you define any other component of your system: in version control, with tests, behind code review. There is a YAML config option and even a visual builder now, but the center of gravity is code, and everything else compiles down to the same primitives.
Model-agnostic. The default path is Gemini, and the integration is deepest there. But ADK works with anything in Vertex AI Model Garden, and through LiteLLM it routes to Anthropic, Meta, Mistral AI and others. The agent abstraction does not care which model fills the reasoning slot.
Deployment-agnostic. An ADK agent is ultimately a container. You can run it on Cloud Run, GKE, your own metal, or hand it to Vertex AI Agent Engine and let Google operate the runtime. The framework does not hold your agent hostage to a hosted service.
Figure 1 · the full map
Six layers, three protocol edges, one lifecycle
If you want the framework-neutral anatomy before the Google-specific tour, the six components of an agentic system are laid out in a piece worth reading first; this article is what those components look like when one vendor builds the whole spine.
The agent taxonomy
ADK has one question at the center of its agent model, and once you see it, the whole taxonomy snaps into place: who decides what happens next?
If the answer is "the model," you want an LlmAgent. It carries an instruction, a model, and a set of tools, and at each turn the LLM reasons about whether to answer, call a tool, or hand off to another agent. This is the classic dynamic agent, and for open-ended work it is the right default.
If the answer is "you," you want a workflow agent. SequentialAgent, ParallelAgent, and LoopAgent are deterministic controllers: they do not consult a model to decide execution order. The model does the thinking inside each step; the structure between steps is yours, fixed, and testable. And if neither fits, BaseAgent lets you write custom control flow directly.
Here is the smallest real agent, in full:
Code 1 · a complete agent
Notice what is absent. No server scaffolding, no JSON schema by hand, no glue between the function and the model's tool-calling format. The framework derives the tool declaration from the Python signature and docstring. That is the "feels like software development" promise in its smallest form.
Figure 2 · the taxonomy
One question sorts every ADK agent type
Who decides what runs next?
Most agent failures I see in the wild are orchestration failures wearing a model costume. The team wired five agents into a free-form conversation and hoped the LLM would impose order. It did not, because imposing order is not what LLMs are for. ADK's answer is to make the orchestration layer explicit and boring, in the best sense of the word.
SequentialAgent runs sub-agents in a fixed order, every time. ParallelAgent fans sub-agents out concurrently, which matters when two checks are independent and latency is money. LoopAgent repeats its sub-agents until something escalates or a max_iterations ceiling hits. The escalation mechanic is worth knowing precisely: a sub-agent or callback sets actions.escalate = True, which is the universal break statement; Guillaume Laforge's loop-agent walkthrough covers the before/after callback patterns for exiting cleanly.
Code 2 · composed orchestration
Figure 3 · three patterns
Sequential gives order. Parallel gives speed. Loop gives iteration.
Tools: where agents touch the world
An agent without tools is a chat window. ADK's tool story has three tiers, and you will likely use all of them in one system.
Function tools are plain functions, as in Code 1. Built-in tools ship with the framework: Google Search grounding, code execution, and friends. And MCPToolset connects your agent to any server speaking the Model Context Protocol, which is fast becoming the default for the tool ecosystem worth connecting to. ADK also wraps LangChain and LlamaIndex tools directly, so an existing investment there is not stranded.
Code 3 · wiring MCP
The seam between your agent and that MCP server is exactly where production reliability lives, and hardening the server side of the contract is its own discipline; the production guide for MCP servers covers auth, schema versioning, and blast radius properly.
The debugger you did not expect
This is the feature that converts skeptics, so I am giving it its own section. Run adk web from the directory above your agent folder and you get a local development UI in the browser: a chat pane to talk to your agent, and behind it, the entire execution unrolled. Every event. Every function call with its arguments and response. Every model turn, inspectable.
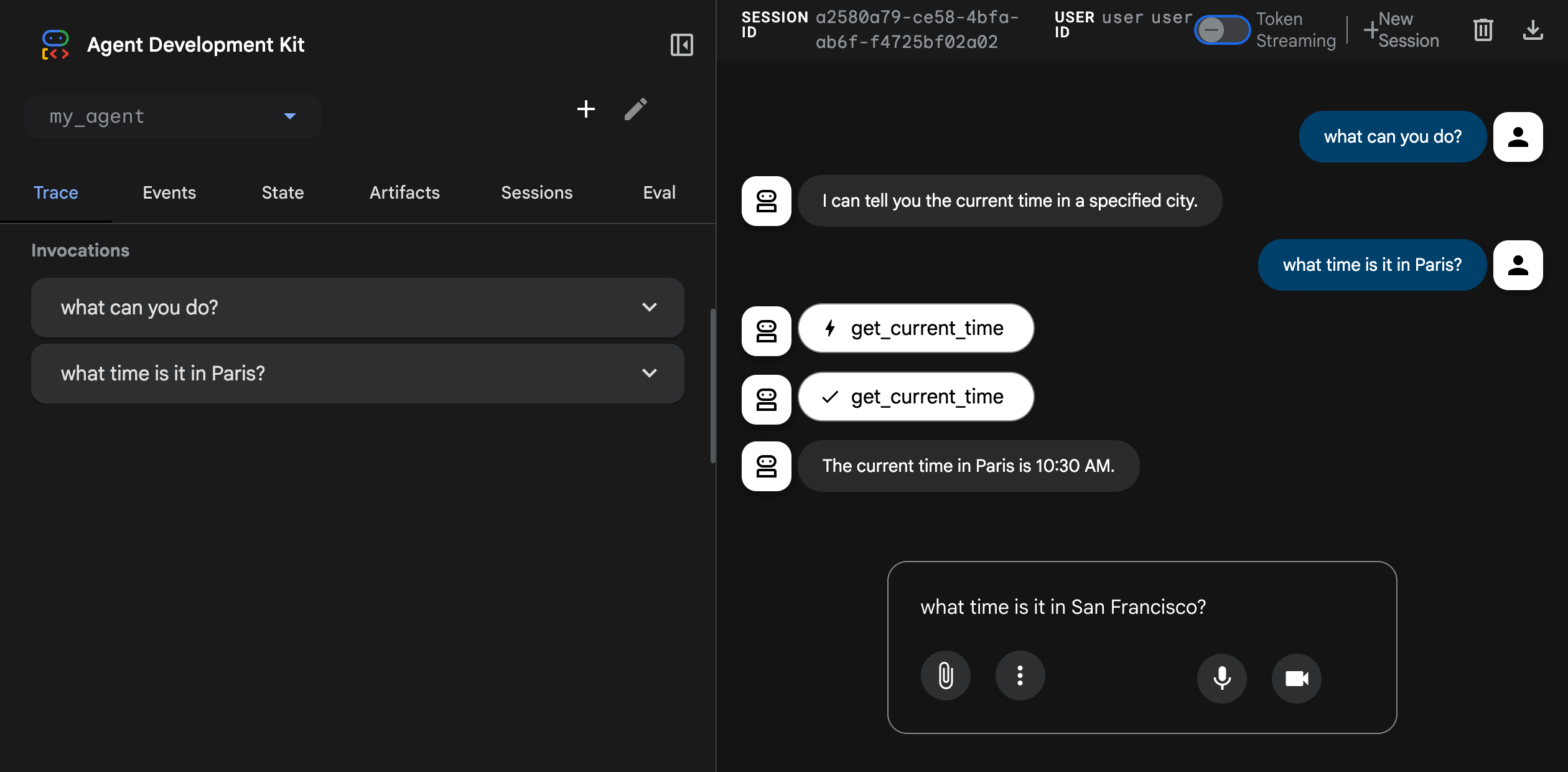
Click into any function call and you see what the model sent and what came back. This sounds small. It is not. The standard failure mode of agent development is staring at a wrong final answer with no idea which of nine intermediate steps bent it. The trace view turns that archaeology into a click.
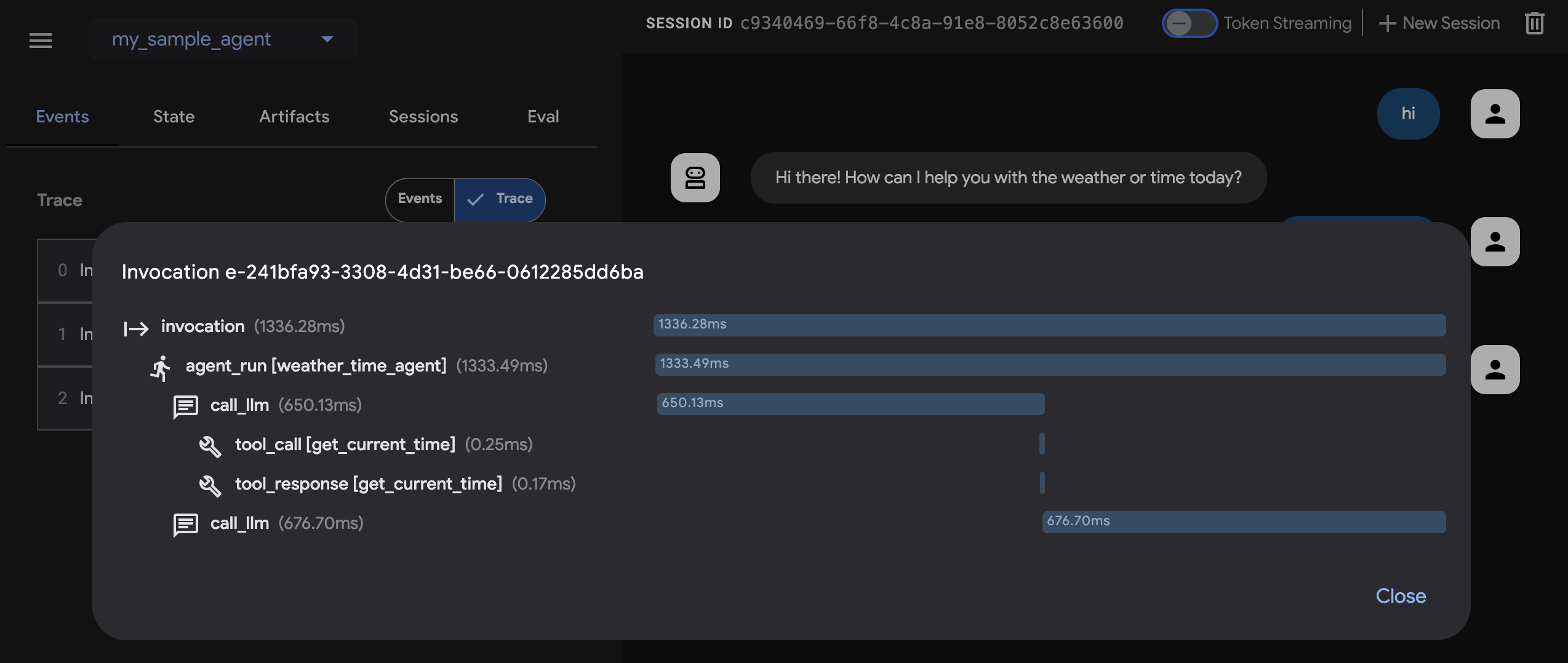
Two siblings round out the local story: adk run gives you the same agent at a terminal prompt, and adk api_server stands it up behind an HTTP API for integration testing. Same agent code, three surfaces, zero scaffolding written by you.
Why this matters
Evals live here too. The dev UI can save a conversation as a test case and run it against your agent as you iterate, checking both the final response and the tool trajectory: did the agent call the right tools, in the right order, with the right arguments? That second check is the one that catches regressions before your users do. The eval docs cover the file formats and the adk eval CLI for CI.
The part everyone skips
Sessions, state, and memory
Here is the unglamorous truth about production agents: most of the engineering is state management. ADK is unusually opinionated about this, in a good way, and the vocabulary pays off later when the managed runtime takes the burden over.
A session is one conversation: its events, and a scratchpad dictionary called session.state. Agents read and write that state, and the cleanest way to chain pipeline stages is the output_key parameter: an agent's final response is written into state under that key, and the next agent's instruction template references it.
Code 4 · state chaining
Sessions need somewhere to live, and that is the SessionService: in-memory while you develop, a database when you self-host, or the Vertex AI managed service when you deploy to Agent Engine. Beyond the single conversation, a MemoryService gives agents searchable recall across sessions; "what did this customer ask about last month" becomes a query, not a redesign.
Figure 5 · where state lives
Turn, session, memory: three radii of recall
Three protocols, three directions
The protocol story is where ADK stops being one framework and starts being a position on how the whole ecosystem should fit together. The cleanest summary I have seen calls it a three-layer architecture: MCP for tools, the framework for agent logic, A2A for agent-to-agent collaboration. I would add the newest edge, A2UI, pointing at the user.
MCP (agent → tool) you have already seen: MCPToolset consumes any compliant server. A2A (agent → agent) is the Agent2Agent protocol, now under Linux Foundation governance, and ADK ships both directions of it. Exposing an agent takes one wrapper, which auto-generates the agent card that other agents discover at /.well-known/agent-card.json. Consuming a remote agent takes one class, and the remote agent drops into your tree like any local sub-agent.
Code 5 · A2A in both directions
A2UI (agent → user) is the youngest of the three and the most quietly radical, still more direction than shipped standard. Instead of returning a wall of text, the idea is that the agent streams a declarative JSON description of an interface (cards, forms, pickers) and the client renders it with its own pre-approved native components, so an agent "generates the interface which best suits the current conversation." Crucially it would be messages, not executable code, so the client keeps control of what can render, and it can ride transports like A2A. Early and unsettled, but it is the missing limb everyone can see coming: agents that finally answer with an interface instead of an essay.
Figure 6 · the triad
One agent, three protocol edges, three audiences
Against the field
You do not pick a framework in a vacuum, so let me put the comparison on the table honestly. The serious alternatives are LangGraph and CrewAI, and the honest framing (argued well in the state-management read on that choice) is that you are picking a bet, not a winner.
LangGraph's bet is graph explicitness: every node and edge visible, every state transition yours, maximum portability across clouds. You pay for that control with assembly: sessions, eval, deployment, and UI are mostly yours to wire. CrewAI's bet is role abstraction: describe a team, get collaboration, fastest path to a working prototype. The cost shows up later, when you need to see and control exactly what the abstraction is doing. ADK's bet is the lifecycle. Not the cleverest single abstraction, but the most complete loop: build, debug in a real UI, eval, deploy to a managed runtime, govern in an enterprise registry, with three protocol edges built in.
And the gap, stated as plainly as the pitch: ADK's workflow agents cover sequence, fan-out, and iteration, but arbitrary conditional graph topologies still require manual wiring today. A GraphAgent proposal (directed graphs, checkpoints, human-in-the-loop interrupts) is in flight, and graph workflows are part of the v2.0 alpha. If your problem is a gnarly DAG with branching everywhere, LangGraph is still the sharper tool this quarter.
Figure 7 · the honest grid
Three frameworks, three bets
The GCP gravity well
Everything so far runs anywhere a container runs. But the reason ADK exists, commercially speaking, is the paved road into Google Cloud, and it is worth seeing exactly what that road hands you at each exit.
Exit one: Cloud Run. adk deploy cloud_run containerizes the agent and ships it. You keep full control of networking, the web surface, and cost shape. This is the pragmatic default for teams that already operate services.
Exit two: GKE or any container runtime. Same container, your cluster, your rules. Nothing about the agent changes.
Exit three: Vertex AI Agent Engine. The managed, agent-native runtime. You wrap the agent in an AdkApp and call create; Google handles, in the Cloud blog's own words, "agent context, infrastructure management, scaling complexities, security, evaluation, and monitoring." The session and memory services you coded against in-memory become managed services with no code change; that is the payoff of the state vocabulary from earlier.
And past deployment sits the registry layer: agents on Agent Engine can be registered into Agentspace, Google's enterprise agent hub, where employees discover them and platform teams keep centralized governance. That last hop, with its IAM boundaries, eval gates, and policy callbacks, deserves its own treatment, and the governance half of this story has exactly that playbook.
Figure 8 · three exits
Same container, three operating models
The feature radar
ADK has been shipping at a pace that makes any static writeup decay, so here is the current edge of the surface, scannable. Treat anything marked alpha accordingly.
SDKs
Python + Java
Python is stable and first; a Java SDK shipped alongside it at Google I/O 2025, with Go and TypeScript ports on the roadmap.
Authoring
YAML agents + visual builder
Declarative agent configs and a drag-and-drop builder compile to the same primitives. Code stays the source of truth.
Streaming
Bidirectional audio and video
Native voice and video agents via the Gemini Live API, with streaming wired into
adk web for local testing. Few frameworks have this built in.Observability
OpenTelemetry tracing
Spans for every agent step and tool call, exportable to your existing OTel stack; on Agent Engine it is on by default with
enable_tracing.Orchestration
GraphAgent (v2 alpha)
Directed-graph workflows with conditional edges, checkpoints, and human-in-the-loop interrupts. The proposal is public as adk-python issue #4581.
Catalog
Agent Garden
Google's library of sample agents and patterns; the fastest way to steal a working architecture rather than invent one.
The walkthrough: order-ops triage, end to end
Theory earns nothing until it ships, so let us build the system this article has been circling: an order-operations triage agent for an e-commerce enterprise. The requirements are the boring, real kind. Customer order issues arrive in a queue. Each must be classified, checked against the ERP for fraud and stock, resolved per policy, and summarized for the human ops team. Refunds above a threshold must go through the finance team's own agent, which is not ours and not built on our stack.
Watch how each requirement maps to a primitive you have already met.
01The specialists
Code 6 · the specialists
02The remote colleague
Finance owns refunds. Their agent runs on their infrastructure, behind their controls, and we consume it over A2A. One class, and their service joins our agent tree:
Code 7 · cross-team, cross-framework
03The pipeline
Code 8 · assembly
Figure 9 · the build
Order-ops triage: every box is a primitive from this article
04Prove it, then ship it
Before deploy, the eval gate. We save known-good sessions from adk web as an evalset: a damaged-item case, a fraudulent refund attempt, a stock-out requiring backorder. adk eval replays them in CI and scores both the responses and the tool trajectories. If a refactor makes the resolver stop calling the fraud check, the build fails before a customer ever sees the regression.
Then, the part that used to be a quarter of platform work:
Code 9 · the deploy
What you did not build
Count the absences: no web server, no session database, no trace pipeline, no scaling config, no JSON schemas for nine tools, no message bus between agents, no auth gateway for the finance integration. The triage logic, the instructions, and the eval cases (the parts that are actually your business) are the only things you wrote. That subtraction is what "simplifies deployment and management" means in practice, and from here the agent is one registration away from org-wide discovery in Agentspace.
05Keep building
The walkthrough above is deliberately compact: one use case, the happy path, the managed deploy. The full reference lives at adk.dev, and it is worth a slow read; the runtime, callbacks, evals, and streaming sections in particular cover the machinery this article only gestured at.
When you want a second build, do the official agent team tutorial. It walks you through a progressive Weather Bot team: you start with a single weather agent, then layer on multi-model support through LiteLLM (Gemini, GPT, and Claude in the same team), split greetings and farewells into specialized sub-agents with automatic delegation, persist the last city checked in session state, and finish with callback-based safety guardrails that inspect inputs before the model or a tool ever sees them. It is the same primitives you just watched, assembled in a different order, and because it wires up the Runner and SessionService by hand, it fills in exactly the plumbing the managed path let you skip.
Should you adopt it?
The counterpoints first, because they are real. The paved road is GCP: ADK runs anywhere, but Agent Engine, managed sessions, default tracing, and the Agentspace registry do not follow you to another cloud, and practitioners evaluating the managed path have found it younger than Cloud Run flexibility in places (Agent Engine is API-only exposition, for one). Arbitrary graph topologies need the v2 alpha or manual wiring until GraphAgent lands. And the ecosystem is younger than LangChain's, even if MCP support neutralizes most of that gap.
With that on the table:
Adopt ADK ifYou are on GCP or Agentspace already, you want eval and debugging built into the framework, your workflows fit sequence, fan-out, and iteration, or you need A2A interop on day one.
Wait ifYour orchestration is a dense conditional DAG (watch GraphAgent and v2), or your platform team cannot absorb an alpha dependency in the control path.
Skip ifMulti-cloud portability is your binding constraint and the managed runtime is the only reason you came. The framework travels; the gravity well does not.
My read, having watched this space professionally for years: the agent framework war will not be won by the cleverest abstraction. It will be won by whoever makes the unglamorous parts (state, evals, tracing, deploy, governance) disappear with the least ceremony. ADK is the most complete attempt at that I have seen, and it is the only one whose vendor runs it in production at consumer scale.
Try it in five minutes
pip install google-adk, write the twelve lines from Code 1 into my_agent/agent.py, run adk web from the parent directory, and open the browser. You will be chatting with your agent and reading its traces before your coffee cools. The official quickstart has the folder layout, and the MCP-to-A2A codelab is the best next hour you can spend.
That is the full map. The platform is a lifecycle, the primitives are few and composable, the protocols point in three directions, and the distance from laptop to managed production is one function call. What you build at the center of it is the part that was always yours.
Comments (9)
Join the discussion
Sign in to comment, bookmark threads, and continue lessons across sessions.